Issue #104 - Using Test Sets to Evaluate Machine Translation


Introduction
There is finally a growing acceptance in some circles that evaluation of Machine Translation (MT) is lagging behind progress in Neural MT (NMT). Especially with regards to metrics such as BLEU, there is a recognition that “as NMT continues to improve, these metrics will inevitably lose their effectiveness” (Isabelle et al., 2017). In today’s blog post, we look at another method of evaluation, that of test sets. These are common in software engineering, and have been used previously in MT some time ago (King and Falkedal (1990)). More recently, Isabelle et al. (2017) used this same approach in order to evaluate the strengths and weaknesses of Neural Machine Translation systems over Phrase Based Machine Translation (PBMT) ones. They showed that NMT is systematically better than PBMT even when the difference in BLEU scores are small. This comparison has been explored by others already (see Isabelle et al. (2017) for details), and our focus today is on the use of test or challenge sets as an evaluation approach.
Approaches
Isabelle et al. (2017) regard test sets as another means of evaluation which can complement existing ones, and are more appropriate for targeting specific linguistic phenomena. This realisation is also apparent in the wider domain of Natural Language Processing (NLP), where most recently Ribeiro et al. (2020) investigate how test sets can detect critical failures, and they establish a framework for generating test cases. While for some NLP scenarios, such testing for specific NER tags is more clear cut, this is more difficult in MT where not only is MT output non-deterministic, but there is a range of acceptable translations. Like King and Falkedal (1990) before them, Isabelle et al. (2017) curate a small, carefully crafted test set- written to test specific phenomena. This differs from Sennrich (2016) who also uses test sets for evaluation purposes, but follows the approach of automatically inverting the reference to create a test set.
The idea of combining test sets into large test suites is not a new one. Lehmann et al. (1996) developed an extensive framework for the construction and customisation of test suites in NLP, including an annotation methodology, categorisation scheme, storage and retrieval system. With planning, the test suites can be reused and extended more easily.
King and Falkedal (1990) advocate test suites in defining an “evaluation strategy for a translation service”, which may seem like a slightly different use case than that of Isabelle et al. (2017), but similarly aim to pick a system which seems most robust overall. They acknowledge that what constitutes a ‘best’ system depends on the requirements but that it should be possible to define tests which capture and evaluate relevant functionality. While in their case this was to evaluate an MT system before purchase, in a commercial MT setting this could be to evaluate a particular model configuration out of several. They point out that the evaluation methods at the time (1990) which were “intelligibility, fidelity or clarity”, and counting the number of required postedits, did not enable “assessment of actual acceptability of the translation quality to the users”. Arguably, this is even more the case now, particularly in cases where systems are judged largely by automatic metrics such as BLEU.
In crafting the test sets, both King and Falkedal (1990) and Isabelle et al. (2017) point out that there may be errors elsewhere in the test sentence but that the test is on one specific phenomenon. Problems can arise with the interaction of different linguistic phenomena so tests need to be cleverly crafted to ensure that this is avoided where possible. King and Falkedal (1990) advocate attempting to avoid ‘noise’ introduced by the choice of lexical item, for example, or the passive voice, if these are not the focus of the test. This can be inadvertent, and Isabelle et al. (2017) try to keep their tests very short in order to avoid that. This is not a solution if you want to test long distance dependencies. Isabelle et al. (2017) base their 108-sentence challenge set on English-> French and craft their test set based on areas where the source and target differ, classifying the types they focus on as:
- morpho-syntactic, where the errors result from a richer morphology in one language
- lexico-syntactic, where a particular lexical item invokes a different syntactic pattern in source from target
- purely syntactic divergences
 Isabelle et al. (2017) have 3 bilingual native speakers (not translators) acting as annotators, who make a binary judgement- success or failure- for the issue being tested. The annotator agreement (as seen in the final column below) is high.
Isabelle et al. (2017) have 3 bilingual native speakers (not translators) acting as annotators, who make a binary judgement- success or failure- for the issue being tested. The annotator agreement (as seen in the final column below) is high.
Insights
In terms of test data, they use the LIUM WMT 2014 shared-task data. For PBMT they include 2 systems (details in 4.2 of paper). For NMT they compare a basic single-layer NMT model (details in 4.3 of paper) and Google’s (Dec 2016) NMT.
Their results show a large difference in scores for test sets yet very small BLEU differences, as illustrated in the table below, extracted from their paper: 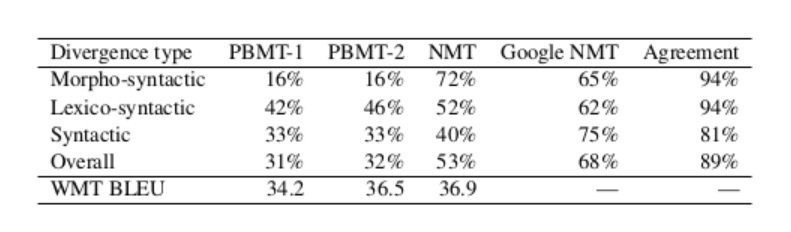 They display success rate grouped by linguistic category (aggregating all positive judgements and dividing by total number of judgements), in addition to the BLEU scores on the WMT 2014 test set. Overall, NMT performs much better than PBMT, as detailed in depth in the paper, while there are a few issues that continue to be problematic for NMT. Of course these results are now a couple of years old, and so will have changed. However, the point remains: BLEU is inadequate for proper evaluation of machine translation output. As they stress, other evaluation tools will still be necessary but test sets provide another dimension to an evaluation strategy.
They display success rate grouped by linguistic category (aggregating all positive judgements and dividing by total number of judgements), in addition to the BLEU scores on the WMT 2014 test set. Overall, NMT performs much better than PBMT, as detailed in depth in the paper, while there are a few issues that continue to be problematic for NMT. Of course these results are now a couple of years old, and so will have changed. However, the point remains: BLEU is inadequate for proper evaluation of machine translation output. As they stress, other evaluation tools will still be necessary but test sets provide another dimension to an evaluation strategy.
For use of MT in commercial settings there are a range of obvious issues which are important for the customer or end user, and can usefully be tested. These range from ensuring that numeric data is correctly translated, that instances of negation are not distorted, and named entities are correctly represented, particularly where the company in question may have very specific company nomenclature or other business crucial terms. Using MT in a commercial setting presents particular challenges, as was highlighted by Levin et al. (2017), where they talk of ‘business errors’ for their Booking.com NMT use case. They explain that for them, the cost of mistranslating “Parking is available” to mean “There is free parking” is significant.
In summary
Test sets can come in many forms, ranging from generic tests, to tests that evaluate on very specific linguistic phenomena, to customer-specific ones. Creating them per language pair is a huge task, but they provide another means of evaluating machine translation output in a more systematic manner, and are complementary to existing evaluation metrics.Dr. Karin Sim
All from Dr. Karin Sim
Related Articles
