From text to audio: how TrainAI enabled multilingual AI for a global consumer electronics giant
A global consumer electronics leader had a goal to make their technology available with real-time translation and face-to-face interpretation across five key markets. With ambitious timelines and varied technical needs across markets, the client needed a partner capable of delivering enterprise-grade data services, consistency and quality across languages and cultures. TrainAI by RWS delivered an integrated approach, by combining proprietary technology platforms with deep multilingual expertise and scalable processes. The client’s vision was turned into measurable results across multiple markets and languages.
453,000 audio recordings delivered across five languages and five major markets
141,000 sentences of synthetic text generated for ASR training
130 AI data specialists from the TrainAI community
Upgraded client ASR capabilities across real-time translation and voice recorder applications
From text to audio: how TrainAI enabled multilingual AI for a global consumer giant
As voice recognition technology becomes increasingly central to mobile device experiences, the demand for high-quality, multilingual AI training data has never been greater. Consumer electronics companies need advanced solutions that can handle multiple languages, cultural nuances and complex technical requirements.
A leading global consumer electronics brand discovered this firsthand when working to enhance its automatic speech recognition (ASR) engines. Their goal was to make the technology available for real-time translation and face-to-face interpretation across five key markets.
To take on this ambitious project, they partnered with TrainAI by RWS, leveraging our comprehensive AI data services to deliver both text synthetic data generation and professional audio data collection at an unprecedented scale.
Here's how we helped turn their vision into measurable results across multiple markets and languages.
Background: enhancing global voice recognition capabilities
The global consumer electronics leader needed to significantly improve its ASR engines, which power real-time translation and interpretation features. This enhancement spanned five critical markets: Australia, Russia, China (Hong Kong), Indonesia and French Canada.
The brand also needed to train its AI systems to recognize named entities in each language. Named entities are words or phrases that refer to specific things like names, products, organizations and locations.
They required hundreds of named entities for some of the languages they focused on:
Indonesian: 630
French (Canada): 151
English (Australia): 138
Russian: 77
Chinese (PRC): 17
Overall, the project required two core capabilities:
Producing realistic, conversational, professional-grade audio recordings to validate and strengthen ASR performance
Each market was managed by a separate client R&D center with distinct requirements for volume, domains and quality standards. This created a complex coordination challenge that required specialized expertise and scalable solutions.
With ambitious timelines and varied technical needs across markets, the client needed a partner capable of delivering enterprise-grade data services while maintaining consistency and quality across languages and cultures.
Challenges
Fragmented requirements across R&D centers
Complex audio recording scenarios
Multilingual conversational synthetic data generation
Quality control at scale
Navigating complexity across markets and languages
Combining proprietary technology, linguistic expertise and scalable processes
Advanced synthetic text data generation workflow
Multilingual prompt engineering
Comprehensive normalization and quality assurance
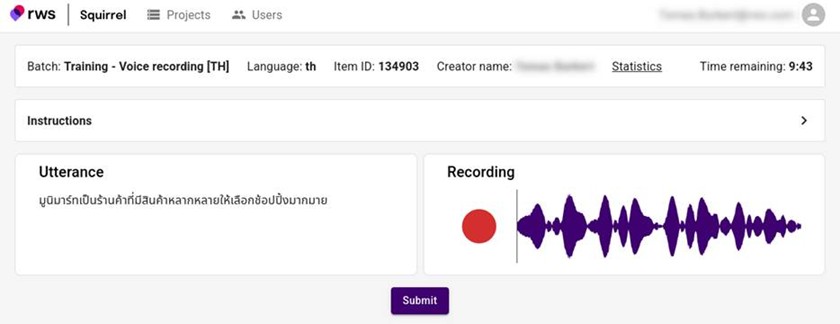
Squirrel: TrainAI’s proprietary audio data collection platform
Results
Delivered 453,000 audio recordings and 141,000 synthetic text sentences
Measurable impact across five languages and five markets
A large-scale project delivered on time with streamlined production efficiency
Positive response from client R&D centers on TrainAI's delivery and approach
Transformed voice recognition through expert multilingual data services
Challenges: navigating complexity across markets and languages
Success across five distinct markets
Quality control at scale
Large-scale project delivered in 4 months
The project presented several challenges that required both technical expertise and cultural understanding:
Fragmented requirements across R&D centers
Each of the five R&D centers operated independently, with different AI data volume requirements, domain specifications and quality criteria. Some R&D centers requested data in more than 100 domains with minimal guidance provided, while others demanded data generated to precise specifications. These included thousands of conversations, utterances on specific topics and recorded discussions containing designated names and words.
Addressing these needs required customized processes for capturing audio and maintaining consistency across departments and domains.
Complex audio recording scenarios
The client's initial vision involved having people create unscripted recordings on their devices with highly specific configurations. Devices were required to be positioned at varying intervals within controlled room environments. The scenarios required two strangers to engage in conversations with moderators present. While effective, this approach created logistical and scalability challenges that risked delaying the project. Instead, we proposed generating synthetic conversational data that could then be subsequently recorded.
Multilingual conversational synthetic data generation
Creating plausible, culturally appropriate conversational content across diverse languages added another layer of complexity, since the quality of LLM outputs varies widely across languages and domains.
Quality control at scale
To maintain consistent data quality standards while meeting monthly delivery deadlines, we needed to generate data for multiple client R&D centers and markets in parallel, requiring robust monitoring systems and streamlined validation processes.
Solution: TrainAI's integrated synthetic text data generation and audio data collection platform
TrainAI addressed these challenges by combining proprietary technology, linguistic expertise and scalable processes designed for enterprise-grade delivery.
Advanced synthetic text data generation workflow
Our synthetic text data generation process began with the development of client-approved scripts, which helped us prevent time-consuming rework once recording began. To complete the project, we onboarded 130 native speakers from the TrainAI community to work across multiple batches and markets simultaneously.
We implemented a two-tier approach:
Tier 1: LLM-based script generation: For languages and domains where LLM outputs met quality standards, we used AI to generate complete conversational scripts. We slightly over-generated content to offset potential rejections during audio validation, typically producing 115 scripts to deliver 100 approved recordings.
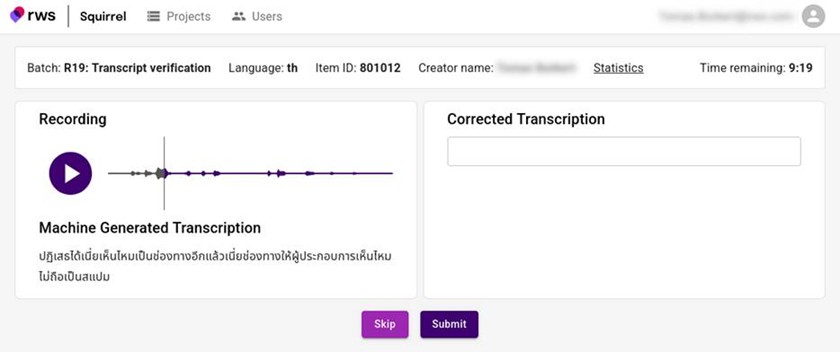
Tier 2: Topic-guided improvisation: When a more natural approach was needed, we used LLMs to generate conversation topics based on client requirements. Native speakers received these topics along with a framework of five subtopics or themes to guide their improvisational conversations. Rather than following scripts, speakers used these topic prompts to create authentic, spontaneous dialogues. The resulting conversations were then transcribed to extract final text content.
Multilingual prompt engineering
Our specialized team created English-language prompts, tested them extensively and then translated them into target languages for better results. Each generated sample went through client review and linguist validation before full-scale production, with ongoing recalibration based on feedback.
To ensure authenticity, we developed advanced prompts, post-editing workflows and cultural validation methods.
Comprehensive normalization and quality assurance
All text outputs were normalized to maintain consistency across markets. This included enforcing style rules such as capitalization, spelling out numbers and ensuring uniform formatting. We combined LLM-based workflows with human review to uphold enterprise-grade quality standards throughout the project.
Squirrel: TrainAI’s proprietary audio data collection platform
To optimize recording, we used our proprietary Squirrel platform, a web-based application built for efficient, high-quality audio data collection. Squirrel enabled speakers to work through queued utterances with integrated recording, review and quality control features.
For dialogue requirements, we recorded speakers separately and then stitched conversations together during post-processing. This approach allowed us to maintain consistency while maximizing efficiency and scalability.
The collaboration transformed the client's ASR capabilities and set new benchmarks for the development of multilingual voice recognition.
Results: delivering measurable impact across global markets
The collaboration transformed the client's ASR capabilities and set new benchmarks for the development of multilingual voice recognition.
A large-scale project delivered on time
TrainAI successfully delivered 453,000 audio recordings and 141,000 synthetic text sentences across five languages and five markets. Most of the delivery occurred within the primary timeline of February to June 2024, with minor extensions into August and December. We achieved this scale while maintaining consistent quality standards and meeting the diverse requirements of each client R&D center.
Streamlined production efficiency
Our Squirrel platform and integrated workflows enabled efficient, scalable processes. The dual-queue system for recording and review, combined with continuous monitoring, allowed real-time quality control and early pattern identification. This significantly reduced production time while improving output quality.
Enhanced product deployment capabilities
The datasets empowered the client to deploy upgraded ASR capabilities across multiple products beyond the original real-time translation focus, including voice recorder applications. The flexible, high-quality data supported faster release cycles and broader product integration than initially planned.
Positive response from client R&D centers
Two R&D centers organized post-project meetings specifically to express their satisfaction with TrainAI's delivery and approach. The level of praise underscored how our solutions exceeded expectations and established TrainAI as a trusted partner for future AI data initiatives.
Transforming voice recognition through expert multilingual data services
By combining proprietary technology platforms with deep multilingual expertise and scalable processes, TrainAI helped a major consumer electronics leader significantly enhance its voice recognition capabilities across diverse markets.
Success across five distinct markets, languages and R&D organizations demonstrates TrainAI's ability to manage complex enterprise requirements while maintaining the agility and quality standards essential for competitive AI development.
Ready to enhance your AI capabilities across global markets? Whether you're building voice recognition systems, expanding into new languages or addressing complex multilingual AI challenges, TrainAI delivers the expertise, technology and scale to turn your vision into measurable results.
Contact us today to learn how our integrated text and audio data services can accelerate your AI development initiatives.
Contact us
We provide a range of specialized services and advanced technologies to help you take global further.