TCWorld Stuttgart 2025 Highlights and Insights


A smaller conference and bigger questions
Walking into TCWorld Stuttgart this year, the first thing that struck me was the size. The main exhibitor hall was noticeably smaller than last year. Some booth reorganization brought some of the exhibitor booths into the foyer, and the addition of large demo “arenas’ with massive monitors had the effect of drawing in crowds of anyone not already committed to a session. Honestly, I think every time I walked by them, they were full to the brim. The main exhibition hall now felt compact rather than sprawling. Efficient, yes, but it did raise a bigger question.
- Are organizations tightening budgets?
- Are fewer teams being approved for professional development travel?
- Or has AI caused executives to mistakenly believe they can reduce the number of humans needed to manage enterprise information?
Many companies faced restructures this year. Some cut travel and training. Some trimmed teams. What is surprising is that some organizations genuinely believe AI can replace the people who create and maintain structured, governed and traceable knowledge. What I hope does not get lost in the noise is this: technical communicators have never been more important.
The truth is simple.
AI is powerful, but it cannot create, maintain or govern institutional knowledge on its own.
It consumes it.
And it is only as accurate as the structures human experts build around it.
Large language models depend on clean, up to date knowledge streams, and by the time an LLM is released, its training data is already stale. Most organizations have no sustainable way to update AI safely. That responsibility increasingly sits with documentation teams who understand semantic structures, versioning, traceability and governed updates.
This puts technical writers, content architects and knowledge designers in a new position of influence. Knowledge specialists are the ones ensuring enterprise “savoir” remains live, structured, traceable and updateable.
LLMs are trained on snapshots that are already out of date by the time the model goes public. Updating them is hard, expensive and brittle.
Technical communicators are now the guarantors of up to date, AI ready knowledge streams that keep enterprise intelligence aligned with real world change.
Why being there in person mattered to me

As someone working 100 percent remotely, these events matter. Conferences are where human connection happens for me. They bring back what remote work quietly erodes: informal exchange, spontaneous conversation, hallway problem solving, and the “real talk” that never happens in a scheduled Teams meeting. Seeing partners, colleagues and friends in person is a reminder of what we lose when collaboration is limited to only virtual spaces.
There is nothing natural about sending a calendar invite just to chat. Conferences bring back the informal exchange, the unplanned ideas, the side conversations that spark real innovation.
And TCWorld has made that clearer than ever.


Once sessions kicked off, one thing became obvious. The community is still strong, still curious and still pushing the boundaries of what content can do. The conversations were sharper. The sessions were punchier. And the focus has shifted from producing information to engineering knowledge ecosystems that feed AI safely, consistently and intelligently.
IA for AI: Structuring Content to Get Better Answers
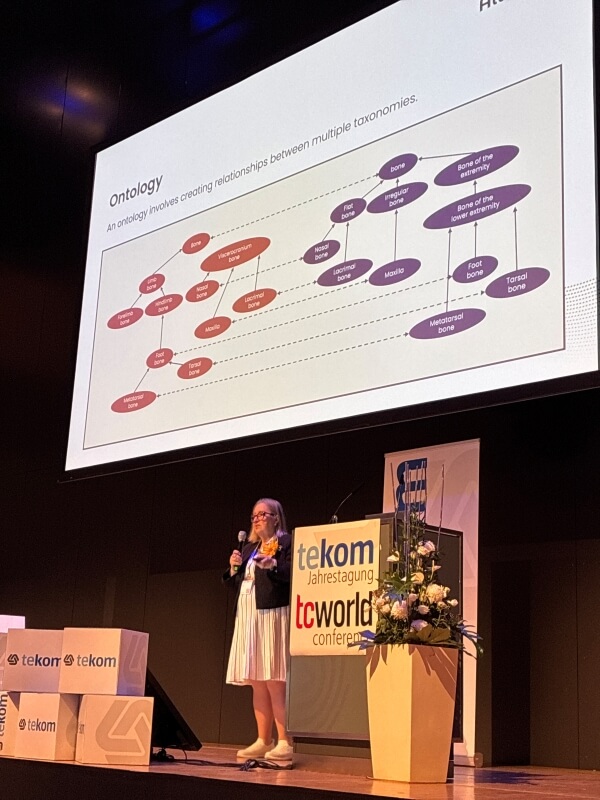
Speaker: Rahel Bailie
Rahel opened with a deceptively simple question:
How do we help machines understand our content the same way humans do?
Her walkthrough of structure levels was one of the clearest I have seen.
- Editorial conventions (visual patterns humans recognise instantly)
- Editorial structures (rules that create predictability)
- Taxonomies (class–subclass relationships)
- Thesauri (associative relationships)
- Lexicons (controlled vocabulary for consistency)
- Ontologies and knowledge graphs (semantic relationships across taxonomies)
Her slides showed how each layer increases clarity for both humans and machines, especially the knowledge graph slide, which demonstrated how concepts connect in multiple dimensions.
Her point was sharp and memorable:
AI is not magical. It is pattern recognition.
If your organization has no patterns, AI has nothing to recognize.
Some standouts from my notes:
- Humans rely on layout cues without thinking. Machines do not.
- Editorial structure is predictable because we design it to be.
- Taxonomies and thesauri turn text into computable relationships.
- Lexicons unify terms across departments and prevent AI drift.
Her examples of inconsistent terminology breaking AI responses hit home.
This session alone was worth the trip.
Don’t Be Afraid of S1000D

Speaker: Pia Grubitz
Pia delivered the friendliest introduction to S1000D I have ever witnessed. Calm, humorous, and honest about its complexity.
Key themes:
- What S1000D is (a 3,700 page specification but the underlying logic is straightforward)
- There are multiple S1000D project versions (A400M, Tiger Helicopter, NH90, Boeing 787, Airbus A350) to name a few
- Where it’s used (defense, aerospace, and now creeping into civil industries)
- Why it exists (high risk environments require uncompromising consistency)
You do not start with every detail. You start with concepts, but Pia delivered it more poetically: “You do not need to know the whole elephant. You just need to know where the elephant is.”
For teams curious about large-scale, multi-partner documentation ecosystems, like aerospace, defense or complex machinery documentation, this session provided grounding and confidence.
Accelerating Global Content Delivery with Structured Learning Content

Speaker: Sarah O’Keefe
Sarah presented a case study from a global certification provider whose entire business revolves around learning materials. Their old workflow depended heavily on InDesign exports, with manual adjustments repeated across languages and variants.
Her illustrated examples of workflows as “spaghetti” and “stupidly inefficient” showed endless, looping review cycles across languages.
Key takeaways:
- Learning content now faces the same reuse and localisation pressures as technical documentation.
- Structured XML is the only way out of the complexity trap.
- Reuse improves quality, not just efficiency.
- Mergers multiply chaos unless a unified structure exists.
The message was clear:
Structured learning content isn’t niche anymore. It’s about to become mainstream.
Hybrid AI Pipelines

Speaker: George Bina
George’s session was a masterclass in combining XML heritage with modern AI without sacrificing control. He showed how structured content, XML pipelines and AI can work together instead of competing.
His use case: automating multi-product press releases
His approach: a hybrid pipeline combining:
- Profiling attributes
- Classical XML transformations
- XProc and XSpec testing
- Generative AI for stylistic adaptation to the company style
His orchestration diagrams made something clear.
AI is powerful, but without structured pipelines, it is uncontrollable.
Key takeaways:
- XML and DITA workflows already solve many AI safety and consistency problems
- AI should be invoked deliberately, not allowed to run wild inside the pipeline
- Prompts should be treated as governed artefacts, just like schemas or stylesheets
- Human review remains essential, but automation dramatically reduces the effort
For anyone planning AI-enabled content automation, this talk was gold.
Building an Azure DevOps Workflow for Large and Distributed Technical Writing Teams
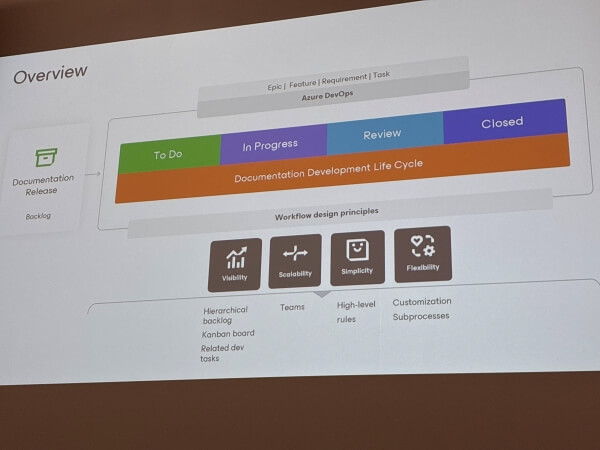
Speaker: Ekaterina Noskova
Ekaterina shared a real-world transformation inside a growing documentation department.
A pragmatic journey from a scattered, multi tool workflow to a unified DevOps based documentation operation.
Key themes from her transcript:
- The team grew from about 10 writers to more than 25 in a short time
- Multiple tools (JIRA, DevOps, Confluence, even email) were causing fragmentation
- They needed visibility, consistency and unified workload management
Her solution:
- Centralize work in Azure DevOps
- Use Epics, Features, Requirements and Tasks to mirror documentation structure
- Integrate documentation states directly into DevOps workflow
- Provide scalability while allowing light team-level customization
The real value was her honesty: every documentation team ends up reinventing processes until they cannot scale anymore.
This talk showed what scaling responsibly looks like.
A Transition from One CCMS to Another: Lessons Learned

Speakers: Eva Nauerth and Peter Shepton
This was one of the most honest migration stories I’ve seen on stage.
Eva and Peter’s presentation on migrating from one DITA based CCMS to another was one of the most honest and practical case studies of the conference. What stood out is that they didn’t leave their old CCMS because of a single catastrophic failure. They left because the system could no longer support the organization they had become.
Their reasons were clear, and every one of them will sound familiar to teams living with legacy content platforms.
1. The old system had accumulated years of technical debt
The “Migration Challenges: Customization” slide showed layers of bespoke tools, outdated scripts and unsupported UI components. They had to “untangle years of custom logic”.
The system was no longer future proof.
2. Content integrity had reached a breaking point
Their repository contained invalid XML, mixed specializations, duplicated topics and inconsistent metadata. Even though both CCMSs were DITA based, “there is no plug and play transfer possible” because the content itself had drifted.
This is classic content debt.
3. Integrations no longer reflected the way the business worked
Legacy connections into translation systems, workflow tools, PIMs and build chains had become brittle and risky. Some integrations were tied to infrastructure that was effectively end-of-life. Extending them further was not an option.
The old CCMS had become an island.
4. Authoring guidelines were inconsistent and impossible to enforce
During the migration they had to rewrite guidelines, retrain business units and align metadata strategies. This tells us the old system allowed variation to creep in over time. Without enforced rules, reuse breaks down and authors work at cross purposes.
A CCMS that cannot enforce consistency is no longer functioning as a CCMS.
5. Scaling across business units was impossible
Their staggered onboarding slide made it obvious: every unit had different tools, behaviors and structures. The legacy system couldn’t unify them.
6. They couldn’t afford to stop production
They made this point repeatedly: production could not pause. The old system made parallel production risky.
The legacy system was too fragile to update while in use.
7. The old CCMS was no longer future proof
Although they never said it outright, the clues were obvious:
- heavy customization
- deprecated components
- outdated integrations
- content too degraded to migrate cleanly
- vendor stagnation or roadmap misalignment
The platform had reached end-of-life. They needed a foundation built for modern DITA practices, metadata governance, multi-system integration and the coming wave of AI assisted content operations.
Long story short
They didn’t leave because the system failed.
They left because it could no longer support their future.
It wasn’t a dramatic failure. It was a slow accumulation of technical debt, content decay, governance gaps and integration limits.
This case study was a powerful reminder that content systems don’t become obsolete all at once, they become obsolete slowly, then suddenly. And it’s usually the teams living inside them who feel it first.
How to Improve the Experience, Quality and Trustworthiness of AI-Enabled Technical Content Delivery

Speaker: Kees van Mansom, Accenture
Kees delivered one of the most grounded talks on AI-enabled content delivery at the conference. Instead of repeating abstract claims about AI transformation, he focused on something far more practical: how organisations can ensure that the answers AI provides are accurate, safe and aligned with user expectations.
The Experience Gap
Users expect personalised, contextual guidance. But most organisations still deliver static PDFs, monolithic knowledge bases or outdated portals. Kees highlighted the widening gap between what customers need and what our content ecosystems are able to support.
AI cannot close that gap if the underlying content architecture is weak.
In fact, AI often amplifies the weaknesses already present.
When AI Fails, It’s a Content Problem
Kees pointed to the common reasons AI produces unreliable results:
- inconsistent terminology
- unclear or missing metadata
- poor variant management
- outdated instructions that appear newer than they are
- and content written for human interpretation rather than machine precision
His examples showed how two seemingly similar pieces of content can produce very different outcomes depending on structure, clarity and consistency.
The message was simple:
- AI cannot apply logic where the content ecosystem contains none.
- The Architecture Problem
Kees walked through the “source of truth” issue that many companies face. Vendors promote elegant, structured pipelines, but the real world is usually a patchwork of legacy files, improvised metadata, scattered repositories and hybrid workflows.
When content lives in this fragmented state, contextual delivery and reliable AI behaviour become nearly impossible.
- AI’s Real Role in Authoring
- pre-checks and validation
- metadata generation
- variant matching
- consistency reviews
- and orchestration of repetitive tasks
- AI accelerates the work of authors who already write in structured, governed environments
- it cannot compensate for lack of structure
- human expertise still anchors the system
- high-quality structured content
- clean metadata
- stable architectures
- and governed pipelines
Unveiling Team Excellence: Expert Interview on CCMS Adoption

Speakers: Dipo Ajose-Coker and Cristina Popescu
Cristina and I unpacked what it really takes for a CCMS rollout to succeed at scale. Not the glossy version teams expect to hear, but the real-world mechanics: governance, psychology, workflow discipline and the early signs that your content operations are mature enough to take the leap.
Drawing from UiPath’s journey, we explored the pivot points that shift a CCMS from “new tool” to “enterprise backbone.” The conversation covered:
- the “why now” moment that pushes teams beyond unstructured chaos
- the shift from blog-style authoring to controlled, structured content
- how metadata, topic typing and information architecture are the hidden engines of scalability
- and how content teams can keep up with continuous delivery without burning themselves out
We also touched on the cultural side: what happens when authors lose the ability to edit everything, how reviewers adapt to targeted assignments, and how cross-functional trust is built through clear SLAs, dashboards and transparent review latency metrics.
This session wasn’t about selling structure. It was about showing that governance, discipline and reuse are the real accelerators of speed, quality and risk reduction.
Key insight:
A CCMS is never a tool deployment. It is an organizational transformation that only works when teams align around metadata, governance and a shared definition of “source of truth.”
From SME Overload to SME Engagement: How to Get Experts to Review Content on Time

Speaker: Dipo Ajose-Coker
My closing session zoomed in on one of the biggest blockers in content operations: getting SMEs to actually review content on time. The slides set the tone immediately.
SMEs are overloaded, unfamiliar with the tools, sometimes skeptical about documentation, and often haunted by bad experiences from previous review cycles.
I walked the audience through the real business cost of delayed reviews. Not abstract “slower processes,” but measurable impacts like missed deadlines, increased rework, customer churn, and nearly one billion dollars lost annually due to inefficient review cycles.
From there, we pivoted to solutions; not nagging SMEs harder, but designing a review journey that reduces friction and amplifies motivation. We covered:
- why SMEs say no (or stay silent)
- how to frame requests so they land with clarity and purpose
- how micro-incentives and appreciation change participation behavior
- using cognitive biases ethically to encourage follow-through
- and why simple process tweaks like smaller assignments, pre-review guidance and difference reports immediately improve turnaround
We also explored an AI-supported model: pre-reviewing content for inconsistencies, flagging risk areas, summarizing changes and making it easier for SMEs to make decisions quickly and confidently.
The message resonated with the room because every content team feels this pain.
Key insight:
SME engagement is not a workflow mechanics issue. It is a behavior-design challenge that succeeds when you reduce cognitive load, increase clarity and support experts with the right tools and AI assistance.
Final Thoughts