Issue #142 - Making something old, new again!


Introduction
In recent years, there has been a tremendous increase in the use of neural networks leading to an increase in demand for hardware resources and higher financial costs. The impact of resource usage has been massive on the environment. We spend a lot of time, resources and money in training a good baseline model but we narrow its usage to a specific domain and language pair. Is it possible to re-use the previously trained models for a different domain and language pair without prior knowledge or modifying the model architecture? In today’s blog post, we will take a look at the work of Kocmi and Bojar (2020) who propose a simple approach to re-use the parent models.
Background
Transfer learning is the idea of utilizing the knowledge acquired in one task to solve related tasks. In the work of Kocmi and Bojar (2018), they made use of subword units to propose a simplified transfer learning technique. It is a warm-start method that involves constructing a shared vocabulary using the parent and child corpora, followed by training the parent model and fine-tuning this model with the child corpora. The authors extend the work of Kocmi and Bojar (2018) by proposing two cold-start approaches which don’t require any prior knowledge about the child corpora.
The Approach
The previous transfer learning approaches (Neubig and Hu (2018); Kocmi and Bojar (2018)) involve separately training a parent model for each different child language pair. In this work, the authors propose two methods to re-use the same parent model for multiple child language pairs.
Direct Transfer: This approach is a simplification of Kocmi and Bojar (2018) and involves fine-tuning the parent model using the child language parallel corpus without changing the vocabulary or hyperparameters. This method relies on the use of subword units in NMT that can handle unseen words by breaking them into shorter units thus enabling the use of parent vocabulary to serve any language pair. The bottleneck to this approach is that it can be sub-optimal splitting the child language words into too many subwords especially for languages using different scripts.
Vocabulary Transformation: In order to tackle the increasing split ratio issue of the Direct Transfer approach, the authors propose a vocabulary transformation method that replaces the parent-specific subwords with the child-specific subwords. The child-specific vocabulary is constructed with the size equal to the parent vocabulary and the transformation preserves the embeddings of the subwords present in both parent and child vocabularies and substitutes the parent-specific subwords in the parent vocabulary with the ones from the ordered list of child-specific subwords.

Fig 1: Algorithm for Vocabulary Transformation
Experiments and Results
Datasets: The proposed approach is evaluated on both high- and low-resource translation tasks across eight different language directions using translation datasets of different sizes (27k - 34.3M segments). For most of the language pairs, the training data is used from WMT (Bojar et al., 2018).
NMT Models:
Parent Model - The English-to-Czech and Czech-to-English winning models of WMT 2019 News Translation Task from Popel et al., (2019) are used as the parent models. The parent model is chosen such that English is on the same side of the parent and child language pair. For instance, an English-to-Russian child has English-to-Czech as a parent.
Baseline - The baseline models are trained from scratch using the same architecture as the parent models exclusively on the child corpus with the child-specific vocabulary only.
Direct Transfer and Transformed Vocab models - The child models are trained for up to 1M steps with a weak early stopping criterion to account for the premature stopping.
Evaluation Metric:
SacreBLEU (Post, 2018) is used to evaluate the performance of the trained models.
Results :
- The model trained with the parent vocabulary using the Direct Transfer method showed significant improvements (0.69 - 4.72 BLEU) over the baseline engine trained using the child-specific vocabulary in both translation directions, except for the Odia and Russian languages.
- The Transformed Vocabulary approach outperforms the baseline performance across all test sets including those where the child languages have different writing scripts than the parent language pair.
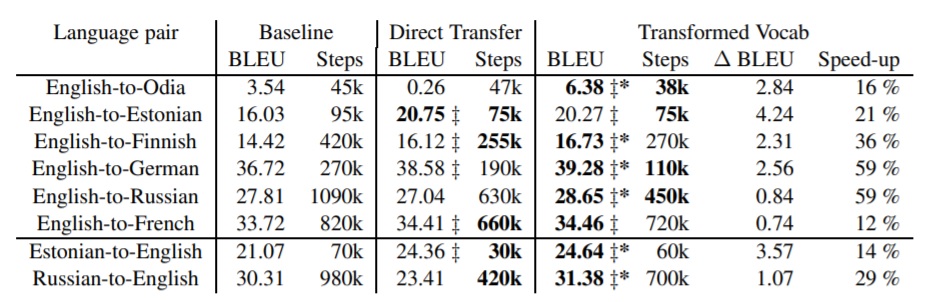
Table 1: Comparison of translation quality and training time
- The Transformed Vocabulary approach outperforms the Direct Transfer approach in most cases.
- There is a 12-59% speed-up in training time using the Transformed Vocabulary approach compared to the random initialization of the baseline.
- The Transformed Vocabulary approach doesn’t outperform the performance of Kocmi and Bojar (2018) in terms of BLEU but shows substantial improvements in terms of training time - two to ten times faster than the Kocmi and Bojar (2018) models.
In summary
Kocmi and Bojar (2020) propose two simple and effective strategies to re-use existing models without requiring a change in model architecture or preparation for knowledge transfer. The two approaches - Direct Transfer and Vocabulary Transformation can be used to re-use NMT models for any “child” language pair regardless of the original “parent” training languages. The proposed methods show significant improvements in terms of both performance and training time across most cases comprising both high- and low-resource training corpus. The authors show that the proposed cold-start approaches are better than the training from scratch approach in most cases. In comparison with the warm-start approach proposed by Kocmi and Bojar (2018), the models trained using the proposed approaches produce a slightly lower performance but show substantial improvements in terms of training time.
Akshai Ramesh
All from Akshai Ramesh
Related Articles
