Issue #101 - Leveraging Monolingual Data with Self-Supervision for Multilingual Neural Machine Translation

Introduction
Multilingual Neural Machine Translation (NMT), which enables zero-shot MT, is a significant development since the invention of NMT. On the one hand, we have evidence that models trained with multiple languages could outperform those trained on a bilingual basis. On the other hand, multilingual NMT also enables us to train models of a language pair where there is no direct parallel corpus available in the training set. This is an important advancement, but we still need more evidence on if it could compete with other approaches, e.g. pivot MT. In this post, we review the method proposed by Siddhant et al. (2020), which leverages monolingual data with self-supervision for multilingual NMT. The results confirmed the two benefits as mentioned above, and it also provided a viable way to add new language without any parallel data or back translation.
Adapting MASS for Multilingual Models
There are many approaches dedicated to improving the performance of multilingual NMT. For example, Chaudhary et al. (2019) used multilingual sentence embeddings to help filter corpora crawled from the web to curate high-quality sentence pairs for the training of low-resource MT. To take advantage of monolingual data for uses in multilingual NMT, He et al. (2019) proposed using self-training with the source monolingual data to increase the training corpus. Chen et al. (2019) introduced the concept of back-translating the target monolingual data to further increase the training corpus by these pseudo- sentence pairs. Siddhant et al. (2020) took advantage of the idea of MASS, proposed by Song et al. (2019) to the training of multilingual NMT. The idea of MASS (Masked Sequence to Sequence Pre-training for Language Generation) is to train a language generation model by masking the input and predicting these “masked” segments, using a decoder-encoder framework. In Siddhant et al. (2020), the models are trained with two objectives, translation objective on parallel data and MASS objective on monolingual data. In this way, we don’t need to produce “pseudo” sentence pairs to make use of monolingual data for multilingual NMT.
Experiments and Results
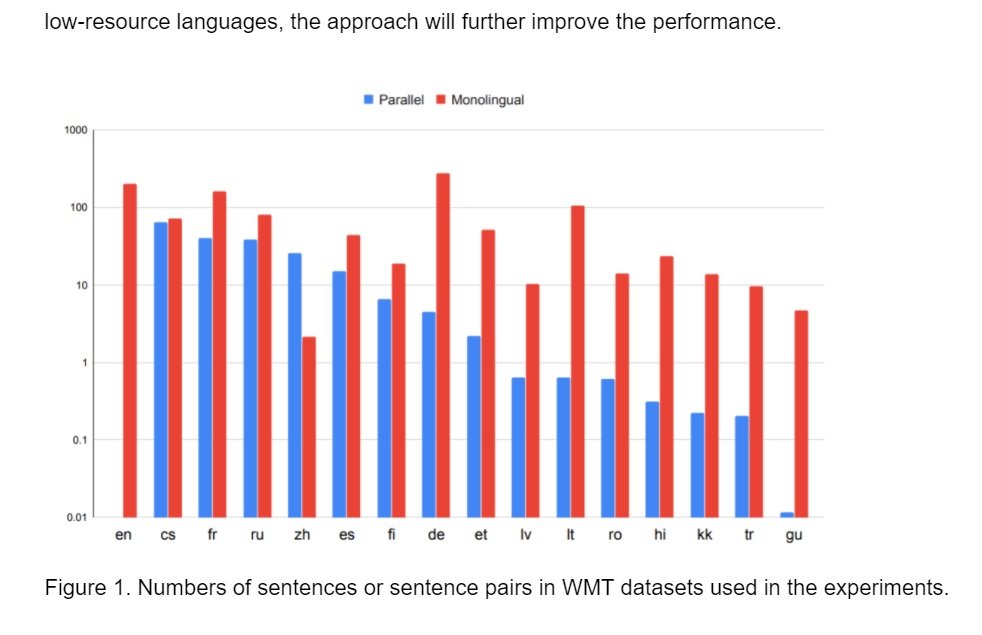
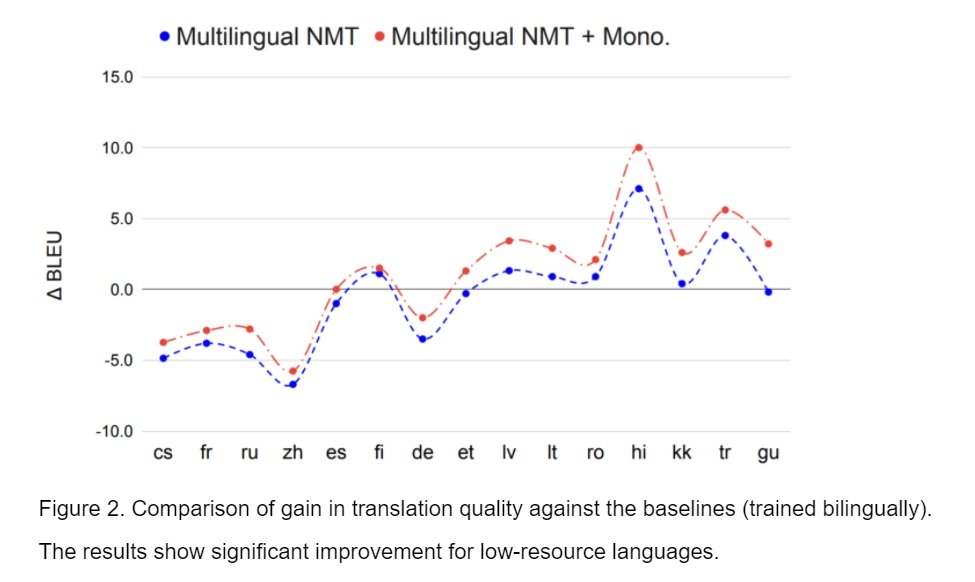
Siddhant et al. (2020) used WMT for the experiments. Fig. 1 shows the sizes of corpora used in the training of models. Fig. 2 presents the performance gain of multilingual NMT models against those trained bilingually for each language pair. The decrease of performance of high-resource language pairs is expected and shown in previous work, but the decrease is alleviated when we introduced the MASS objective on monolingual data in the training. It also shows that for low-resource languages, the approach will further improve the performance.
In summary
In this post we reviewed the use of monolingual data with self-supervision by introducing the MASS objective in the training process. Both the translation objective on parallel data and the MASS objective on monolingual data are used to guide the training. The results show that models trained with the proposed method consistently outperform the models which were not trained with it in multilingual NMT. There is also one experiment on German<>French showing that the approach also outperformed the pivot MT approach. We need to do more experiments to confirm this finding. If the results are consistent in other language pairs, this approach might be one big stride for zero-shot MT. As of 2019, multilingual NMT had only achieved comparable results against pivot MT by making pseudo- sentence pairs before the actual training of models. This proposed method here takes advantage of both parallel data and monolingual data simultaneously in the training, and appears to be a promising approach to zero-shot MT.Dr. Chao-Hong Liu
All from Dr. Chao-Hong Liu
Related Articles
