Issue #128 - Using Context in Neural MT Training Objectives


Introduction
In the paper “Using Context in Neural Machine Translation Training Objectives” (Saunders et al., 2020) we introduce a robust version of Minimum Risk Training (MRT) for Neural Machine Translation (NMT), and show that it can outperform the standard approach while requiring fewer samples. We also summarize work using MRT to address over-exposure to poor-quality tuning data (Saunders & Byrne 2020).Background to MRT
Normally, NMT models are tuned for “maximum likelihood” on training data, but this can cause difficulties:- The model only ever sees training examples. This can cause overfitting: a model might become too effective at translating the training data, but lose the ability to generalize.
- We train for likelihood, but usually want high performance on a translation metric like BLEU.
Minimum Risk Training (MRT) for NMT (Shen et al., 2016, Edunov et al., 2018) aims to address these problems. Under MRT, we sample N model translations for each source sentence. We then minimize their expected risk under some sequence cost function ∆, usually 1 - sentence-level BLEU (sBLEU).
Because this version of MRT operates on sequences, we call it seq-MRT.  With seq-MRT we optimize using model samples, not just training examples. Our objective is based on sBLEU, not just likelihood. There are still difficulties, though. Seq-MRT may need dozens of samples per sentence for good results, due to individual samples often being unhelpful. Additionally, sBLEU is a noisy, per-sentence approximation of document-level BLEU, the usual NMT metric.
With seq-MRT we optimize using model samples, not just training examples. Our objective is based on sBLEU, not just likelihood. There are still difficulties, though. Seq-MRT may need dozens of samples per sentence for good results, due to individual samples often being unhelpful. Additionally, sBLEU is a noisy, per-sentence approximation of document-level BLEU, the usual NMT metric.
Using context in MRT
For a given batch seq-MRT might generate sample translations for each sentence and score each individually.
Figure 1: Toy examples of seq-MRT (left) and doc-MRT (right) scoring, with illustrative scores.
Instead, we introduce context with “doc-MRT”. We order samples into minibatch-level “documents”. Ordered grouping can indicate the quality of each sample in context. For example, giving the same score to the worst translations for each sentence conveys that other sample documents should be preferred. Alternatively, we could group samples randomly into documents: this is faster, but does not distinguish as clearly between sample documents.
Now we can minimize risk under a document cost function ∆ like 1 – document BLEU, instead of scoring sentences individually. If each sample appears in exactly one document, the objective function can be simplified so it’s very similar to the seq-MRT objective – only the ∆ calculation changes.  There is a github demo of the different scoring schemes.
There is a github demo of the different scoring schemes.
Experimental setup
We experiment with English-German NMT and Grammatical Error Correction (GEC), in both cases pre-training a Transformer baseline with maximum likelihood before tuning. For NMT we pre-train on 17.6M sentences from WMT news datasets. We then tune on a separate dataset of 24.2K sentences from WMT validation sets, comparing maximum likelihood estimation (MLE), seq-MRT, and doc-MRT with random and ordered grouping. For GEC we pre-train and tune on 600K sentences from the NUS and Lang8 datasets.Results
All forms of MRT tuning can improve over the NMT baseline, while MLE tuning overfits. With the ordering scheme, doc-MRT improves over seq-MRT. Noticeably, doc-MRT improves over the baseline with just N=4 samples per sentence, while seq-MRT does not.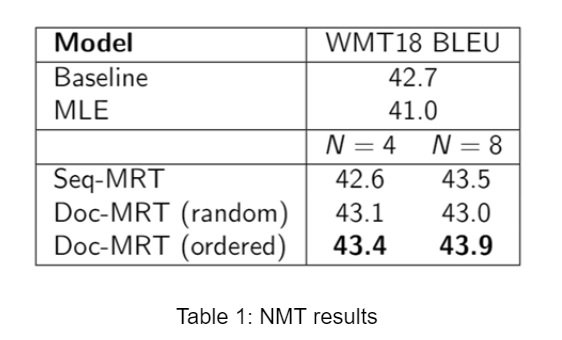 Similar results appear for GEC under the GLEU metric, although here seq-MRT is unable to improve over the baseline for either test set.
Similar results appear for GEC under the GLEU metric, although here seq-MRT is unable to improve over the baseline for either test set. 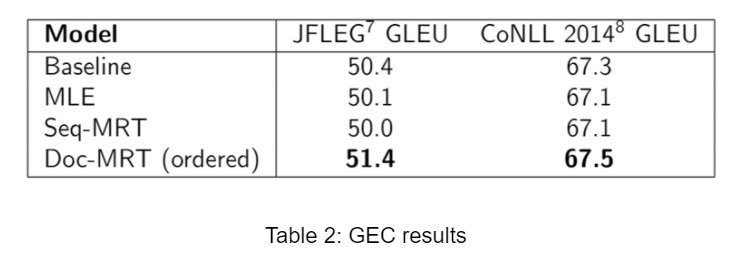
Minimum Risk Training vs Exposure Bias and Hallucinations
NMT can suffer from “exposure bias”. For example, domain mismatch between test and training sentences can cause NMT to generate “hallucinations” that have little to do with the input, and over-exposure to training examples can cause similar problems - using MRT has been shown to help in these scenarios (Wang & Sennrich 2020, Müller et al., 2020).
We noticed a different over-exposure problem: noisy tuning data. While tuning on small datasets of biomedical abstracts, we found about 3% of training examples were slightly misaligned. For example, one English line “[Conflict of interest with industry - a survey of nurses in the field of wound care in Germany, Australia and Switzerland.] Background” was aligned to a German sentence which translates as “Background: Nurses are being increasingly courted by industry.”
Not perfect, but not unusual for automatically aligned training data. But after tuning, the system behaved strangely when given similar sentences. For example, many sentences containing article titles would be translated to the German for Background or Summary - in similar training examples Background was often the only word appearing in both source and target sentences.
A standard approach would be to just remove problematic sentences from the tuning set. However, not only can these be difficult to identify, but we found that removing these examples can hurt performance. Even noisy training examples can contain helpful examples of vocabulary use if data is limited.
We wondered whether MRT tuning could allow better use of these sentences, even though the over-exposure was to noisy translations, not simply to domain mismatched examples. We found doc-MRT tuning improved the overall BLEU score compared to standard tuning and avoided the side-effects of tuning on noisy examples, without needing to know which examples were problematic.
In summary
Minimum Risk Training has benefits when tuning an NMT system, exposing a model to its own samples and optimizing with respect to a real NMT metric instead of likelihood. The doc-MRT scheme has two additional benefits: it gives the model the context of other samples in a minibatch, and it permits optimizing with respect to document-BLEU, instead of sentence-level BLEU. It also works better with very few samples. Finally, we showed doc-MRT can be used to benefit from noisy tuning data, instead of just throwing it away.Dr. Danielle Saunders
All from Dr. Danielle Saunders
Related Articles
