Issue #77 - Neural MT with Subword Units Using BPE-Dropout

BPE-Dropout
The idea of using subword units for MT is highly desirable because it allows us to translate rare words if their subunits are in the training corpus, even when these words themselves are not. This is very useful especially with training of MT systems for low-resource languages. Another advantage to use subword units translation is that it could be applied to non-segmenting languages, e.g. Chinese and Thai. In this case, it can be applied in the training pipeline without the need to introduce a commonly used preprocessing procedure to segment sentences.
The use of byte pair encoding (BPE) in neural MT (NMT), introduced by Sennrich et al. (2016), is the most successful method to allow us to learn these subword units automatically from the parallel corpus. BPE is actually a data compression algorithm which could be used for word segmentation, Gage (1994). The idea is simple: keep the most frequent “segments” (subword units) intact and split others into tokens.
BPE itself as used for NMT is deterministic. To improve from that, Provilkov et al. (2019) proposed the BPE-Dropout method, which will “stochastically corrupt the segmentation procedure of BPE” and thus create multiple segmentations. Fig. 1 shows the comparison of BPE and BPE-Dropout with the word “related” as an example. Fig. 1 (a), from top to bottom, presents how segments are merged in each step of the BPE algorithm. Fig. 1 (b) shows the steps using BPE-Dropout, in which the authors introduced the “dropouts” (in red underlines) where their corresponding segments cannot be merged in a specific step. 
Figure 1. Comparison of subword segmentation for word “unrelated” using (a) BPE and (b) BPE-Dropout, excerpted from Provilkov et al. (2019).
Experiments and Results
Using random subsets extractracted from WMT14 English-French corpus, the experimental results show that BPE-Dropout performs the best for all different sizes of training corpora, ranging from 500k to 4M sentence pairs. However, it also shows that the performance is getting very close with larger training corpora. We will need more experiments on large corpora and more languages to better assess the performance gain of BPE-Dropout.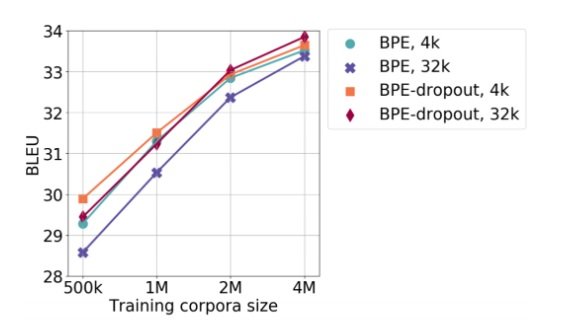
Figure 2. Comparison of performance of BPE and BPE-Dropout, with different training corpora size and vocabulary size, excerpted from Provilkov et al. (2019).
In summary
In this post we briefly reviewed the ideas of using subword units for MT. We also talked about the most popular algorithm used for this matter, BPE and the proposed BPE-Dropout, for NMT. The experimental results show that BPE-Dropout performs the best for all different sizes of training corpora. It seems that the difference won’t be much when we have a large corpus. Notably though, it also indicates that BPE-Dropout will be useful for the training of NMT models involving low-resource languages.Dr. Chao-Hong Liu
All from Dr. Chao-Hong Liu
Related Articles
