
Introduction
Word alignment was a key component of statistical machine translation technology. Although it is not explicitly used in neural machine translation (NMT) models, it is still very useful in the end-to-en NMT pipeline. For example, it can be used to project markup from the source segment onto the translation, or to preserve the source segment capitalisation or spacing. It may also be useful for quality estimation or evaluation. There have been a number of approaches proposed to induce alignments from NMT models. However, with the NMT models being autoregressive, the prediction for a given target word is made given the source words and the previous target words, but ignoring the following target words. In this post we take a look at MASK-ALIGN, a paper from Chen et al. (2021) which proposes to induce word alignment using the full target context.
Approach
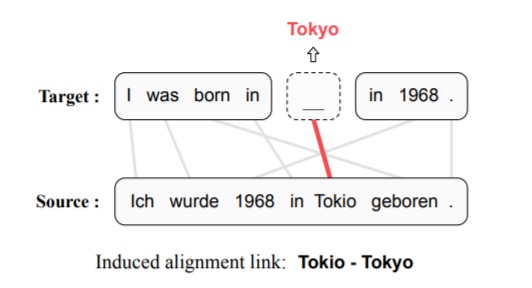
When predicting links considering only the source and previous target words, NMT-based aligners miss important information that can lead to errors. In the figure example below, not knowing that “1968” follows on the target side when predicting the link for “Tokyo”, the engine could align it to “1968” on the source side. To alleviate this problem, some NMT-based aligners guide themselves with pseudo-alignments of the full training data, which is not convenient and expensive to compute. The MASK-PREDICT approach can rely on the full target context and does not need to be guided by additional alignments. This model masks out each target token and recovers it conditioned on the source and other target tokens. The idea behind it is that the source token contributing most to recovering a masked target token should be aligned to that target token. For example, in the figure below, the target token “Tokyo” is masked out and re-predicted. Intuitively, as all source tokens except “Tokio” can find their counterparts on the target side, “Tokio” should be aligned to the masked token.
In practice, alignment links are generated from the attention weights between source and target. Attention weights from two unidirectional models are actually learned, and the model encourages agreement between them during both training and inference. As self-attention is fully-connected, it is modified to prevent the to-be-predicted token itself from participating in the prediction. For efficiency purposes, the prediction of each target token is performed in parallel. In order to avoid the “garbage collector” effect observed in statistical alignment models, when a specific target token is aligned to many source tokens, a so-called “leaky attention” is introduced. Leaky attention is inspired from the “NULL” word to which are linked words with no correspondence on the other side. It provides an extra “leak” position in addition to the encoder outputs.
Results
Although the alignment error rate (AER) has been proved to lead to misleading results, it has been widely used to evaluate word alignment quality in recent research instead of the more accurate precision and recall. The present paper is not an exception and also uses only AER. They observe an improvement of AER with the MASK-ALIGN method in 4 language pairs.
An ablation study shows that the masked modeling plays a critical role since removing it yields a worsening of at least 9 AER points. The ablation study also reveals that leaky attention and agreement-based training and inference are both important.
In summary
Word alignment is still useful in the end-to-end NMT pipeline, to project information from the source segment, or for quality estimation or evaluation. Current approaches are based on autoregressive NMT models, which implies that the predictions of a specific target word are done ignoring the following words. The MASK-ALIGN approach (Chen et al., 2021) masks each target token and re-predicts it based on self-attention, conditioned on the source words and the rest of the target words. It ensures agreement between two unidirectional models and introduces a so-called “leaky attention” for words with no counterpart on the other side. It achieves better AER scores than previous approaches.
Tags:
Language Weaver
Author
Dr. Patrik Lambert
Senior Machine Translation Scientist