

Introduction
Sennrich et al. (2016) proposed an effective segmentation strategy that segments words into subword units. Their method has been widely used in both industry and the research community. It has been proved to be useful for rare word reduction and produces better translation quality in many cases. However, for some particular scenarios such as MT between differently inflected languages and low-resource cases, subword segmentation might not be the best option. In this post, we take a look at a paper by Li et al. (2021) which compared four different segmentation strategies: byte pair encoding (BPE) (Sennrich et al., 2016), character-based segmentation, Morfessor (Creutz and Lagus, 2002) and word-level segmentation. A set of experiments are conducted under three distinct scenarios: translating to languages of different morphological categories, training with low-resource language pairs, and adapting to unseen domains.
Translation to Languages of Different Morphological Categories
Based on the morphological diversity, languages can be classified into different categories: fusional (F), agglutinative (A), introflexive (In) and isolating (Is). In the first experiment, they trained Transformer models from English to eight languages that cover all four morphological categories (two languages per category) using four different segmentation methods: word level, character level (CHAR) , BPE and Morfessor. The selected languages are: French (Fr) and Romanian (Ro) for F, Finnish (Fi) and Turkish (Tr) for A, Hebrew (He) and Arabic (Ar) for In, and Vietnamese (Vi) and Malaysian (Ml) for Is. The training data size is 1M parallel sentence pairs for each language pair.
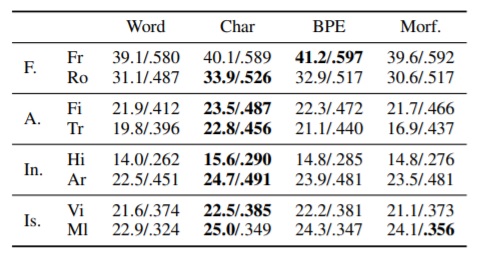
Table 1: BLEU/chrF3 scores of systems translating from English to languages of different morphological categories, using different segmentation algorithms.
Experiment results are shown in Table 1. Models are evaluated using two metrics: BLEU and chrF3. The conclusion is that CHAR outperforms other segmentation methods in most of the cases. The only exception is French, which is similar to the source language English. In this case, it might be beneficial for joint BPE learning.
Impact on Low Resource Language Pairs
In order to investigate which segmentation method is more suitable for low-resource scenarios, they conducted experiments for the language pair English (En)-German (De) and English-Finnish on the dataset of size 50K, 100K, 200K, 500K and 1000K subsampled from WMT data. According to the results, in general, CHAR and BPE perform similarly, but both are better than word level segmentation and Morfessor. The scores of the word-based models is lower than other models for all subsample sizes on both language pairs. Besides the BLEU and chrF3 scores, the recall rates of rare and unknown words are also computed. Under this low resource setting, CHAR achieves the highest recall rates. Although, as the data size increases, the gap between CHAR and BPE reduces gradually.
Impact on Adaptation to New Domains
When applying the segmentation rules learned from the baseline corpus to a different domain data, they might produce improper segmentation on new data and lead to a performance decrease. So the third experiment aims to test how different segmentation methods affect MT translation quality when adapting to other domains.
The data used for this experiment is De-En data (Koehn and Knowles, 2017) which covers four distinct domain subsets: Law, Medical, IT and Koran. To evaluate the performance on each domain, each time, the model is trained only on one domain subset and tested on the other three. Two settings are applied: No Adapt (no target domain data involved) and Finetune (randomly select 100k sentence pairs from target domains to finetune the source domain model).
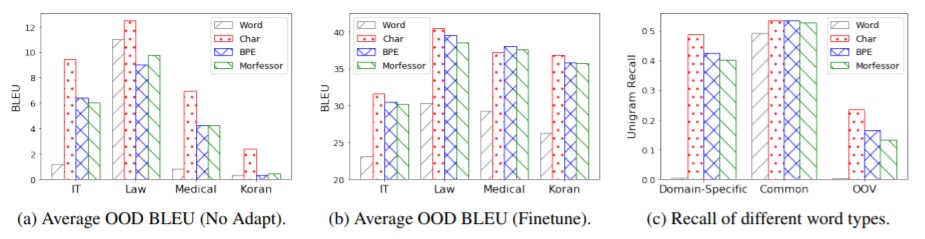
Figure 1: Domain robustness of translation systems based on different segmentation algorithms.
In Figure 1, (a) and (b) show the average out-of-domain (OOD) BLEU scores from different segmentation approaches for four different domains under two settings. In most of the cases, CHAR outperforms the other three methods except the Medical domain from the Finetune model. Word level segmentation continues to be the worst one in all cases. To understand the advantage of CHAR, they also evaluate the CHAR method on three different test sets: (1) Domain-specific words only appear in the target domain training data; (2) Common words found in both source and target domain training data; (3) Out-of-vocabulary (OOV) words can not be found in both training data. Results are demonstrated in (c): the word level method is still the worst one. For the Common words testset, the other three approaches achieve similar results, but for Domain-Specific and OOV, CHAR is still better than the others.
In summary
Li et al. (2021) conducted a series of experiments to systematically compare how different segmentation strategies (word-based, BPE, CHAR and Morfessor) affect MT performance under three common scenarios: translating to morphologically diverse languages; translating with low resource language pairs; and adapting to new domain data. In general, with a data size under 1M sentence pairs, CHAR performs better in most of the cases. Meanwhile, word-based models perform the worst in all settings. However, the low resource case is only evaluated on two language pairs and the domain adaptation experiment is tested on one single pair. So we expect more language pairs can be covered for the further works to draw the final conclusion.
Tags:
Language WeaverAuthor
Dr. Jingyi Han
Machine Translation Scientist