
Introduction
One of the interesting challenges facing current Neural MT systems is that of gender bias. As explained in more detail in last week’s post, Managing Gender Bias in Machine Translation, this refers to a system’s tendency to make gender translation choices that are not present in the source text.
Researchers have made the distinction between “ambiguous” and “non-ambiguous” gender, depending on a word’s use in a sentence. In the English sentence “The nurse asked the doctor if she needed any help,” the doctor here is unambiguously female (based on the pronoun “she”), whereas the nurse’s gender is ambiguous without further context. When translating into a language with grammatical gender, such as German or Spanish, an MT system must explicitly choose a gender for the nouns (e.g. “die Ärztin” or “la doctora”).
Even in non-ambiguous cases, an MT system may choose the wrong gender. The model may fail to understand the link between the pronoun and the associated noun, and instead produce a translation based on whatever gender is most common for that job title in the training data. This can lead to factually and grammatically incorrect translations, as well as a propagation of stereotypes in further data. For more information on how gender bias is introduced in machine translation, you can refer to the earlier issue #23.
De-Biasing Neural Machine Translation with Fine-Tuning
In response to this problem, we worked to improve the output of our engines when translating nouns of non-ambiguous gender, because these are the cases where a model should have enough information to produce the correct translation. Our first research efforts focused specifically on the translation of job titles of binary gender (i.e. male/female).
Following the method outlined by Language Weaver Research Scientist, Dr. Danielle Saunders (Saunders et al., 2020), we fine-tuned two translation models, English to German and English to Spanish, with a parallel dataset of 194 job titles contained in simple sentences like “The doctor finished his work” and “The doctor finished her work” along with correctly gendered translations. Fine-tuning our models means that instead of starting from scratch, trying to edit or create millions of translations so they are gender balanced, and then training a new model for potentially days to see an improvement, we can instead take our pre-existing models, train them a little more on a small dataset that is 0.0005% the size of normal training data, and have an improved result in mere hours. Our hope in doing this was that, upon seeing a balanced mix of male and female forms of job titles, the model would accordingly tweak the parameters that were overly depending on the stereotypes in the training data and subsequently balance out its gender translations.
Results
After fine-tuning our two translation models with this dataset, we could see a significant change in gender outputs. The general translation quality produced by the models (measured with the BLEU metric on our internal test sets) remained the same; but the gender translation choices, measured with the aid of the WinoMT dataset, told a different story. WinoMT (from Stanovsky et al., 2019) is a challenge set for gender bias. Take the sentence “The farmer ran faster than the tailor because she was in shape.” WinoMT would check whether the unambiguous job title “farmer” translates as female. Issue #133 talks about WinoMT more extensively, so we encourage reading more there.
The table below reports the accuracy of the model’s gender choices, i.e. the percentage of sentences where the unambiguous gender was correctly translated. We can see that the fine-tuned models have significantly higher accuracy scores.
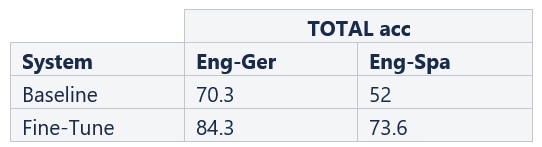
Table 1: WinoMT accuracy scores for the baseline and fine-tune models for Eng-Ger and Eng-Spa
The next table reports F1 scores specific to the two genders. These scores represent a balanced measure between precision (how many of the model’s respective gender choices are correct) and recall (how many of the respective gender choices from the dataset does the model get right). We track this metric to ensure the model isn’t vastly over- or under-estimating the amount of one gender.

Table 2: WinoMT gender-specific F1 scores for Eng-Ger and Eng-Spa
Looking deeper, the WinoMT dataset is labeled “stereotypical” (PRO) or “anti-stereotypical” (ANTI) for every sentence. A stereotypical example is one that agrees with the gender bias; for instance, a doctor that needs to be translated as male. This distinction allows us to analyze how much a model adheres to stereotypes present in training sets.
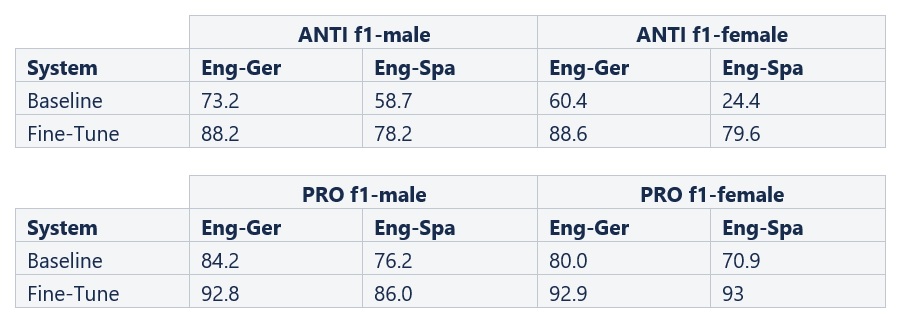
Table 3: WinoMT F1 scores by anti- and pro-stereotype groups
As expected, we can see the baselines were better at translating stereotypical roles than anti-stereotypical ones (e.g., a female plumber). This is particularly prominent in the anti-stereotypical female column, where the F1 was lower than the male equivalent by 13 points for German and 34 points for Spanish.
Not only did fine-tuning drastically even out this discrepancy to have the F1 scores almost balanced for gender in anti-stereotypical roles, but our fine-tuning also greatly improved overall translation of anti-stereotypical gender roles to the point where the difference in accuracy between stereotypical and non-stereotypical translations was more than halved. Essentially, our fine-tuning has across all measurements created better translations of gender, while also weakening the effect of the gender bias present in average training data.
Looking Beyond the Unambiguous
There is more to the story than these promising results. Remember the earlier example, “The farmer ran faster than the tailor because she was in shape.” Given the above results, the model is now more accurate in correctly translating the unambiguous job title, “farmer”, as female. However, what of the ambiguous case, “tailor”? It turns out, our fine-tuning affects these cases as well.

Table 4: Differences in translation before and after fine-tuning; changes in bold
Despite both baselines’ correct translations of the pronoun “she” as female, both job titles were translated as male, creating a grammatical error in gender agreement. After fine-tuning, both models correctly translate “farmer” to agree with the female pronoun — while additionally translating the gender ambiguous “tailor” to be female. Why? Essentially, the fine-tuning has shifted the model to no longer be as sensitive to the male-dominated imbalance in the training data, and instead be more sensitive to any pronoun presented in the sentence, related to the entity or not.
Using the adaptation of the WinoMT dataset created in Saunders et al., 2020, which analyzes how the ambiguous job titles are translated, we can calculate the effect of fine-tuning on gender correlation.
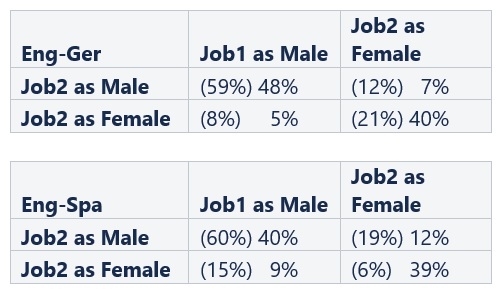
Table 5: Percentage matrices for the gender of Job Title 1 and Job Title 2 translations (baseline score in parentheses)
Before fine-tuning, our models translated around 60% of the sentences to have both job titles as male (just like in the farmer/tailor example). As expected, these numbers lowered significantly after fine-tuning, but sentences with mixed gender lowered slightly as well, making translations with two females the only type to increase — in the German case it doubled, and the Spanish score increased by over 6 times.
In summary
There is no right or wrong answer here. If a human were to translate these, they would either need more context or would translate based off their own preference. It is up to our team at RWS Language Weaver, and those involved in gender bias research to decide together how this human judgment call should translate into our models.
At this stage, it is important to further define what exactly we are trying to achieve when gender de-biasing for machine translation. If de-biasing means simply mitigating the bias present in the training data, then fine-tuning is a good candidate approach, and this is a promising step forward. However, now that we are moving the model away from the training data’s inherent gender imbalance, establishing where we are moving it to remains the open question. Stay tuned to these pages for more, as our research in this area continues.
Tags:
Language Weaver
Author
Katrina Olsen
Research Engineer