
Introduction
In today’s blog post, we will take a look at the work of Wang and Sennrich (2020) who establish an empirical relationship between 2 well-known problems in neural machine translation (NMT): “hallucination” and “exposure bias” and show how training with Minimum Risk Training can help mitigate these problems.
Background
In Neural MT, at training time, the model predicts the current word with the ground truth word (previous word in the sequence) as a context, while at inference time it has to generate the complete sequence. This discrepancy in training and inference often leads to an accumulation of errors in the translation process, resulting in out-of-context translations and is called "exposure bias" Ranzato et al. (2016). Also, NMT sometimes produces “hallucinations”: out-of-domain translations which may be fluent but completely irrelevant and misleading in the given context.
Why does this happen?
The standard way to train NMT is by using the Maximum Likelihood Estimation where the model is trained with teacher forcing and may over-rely on the previously predicted tokens, which leads to error propagation. As the target sequence grows, the errors accumulate along the sequence and the model has to predict under conditions it has not met at training time.
Minimum Risk Training (MRT)
- MRT is a sequence-level objective that avoids this problem. Introduced by Shen et al. (2016), Edunov et al. (2018) showed that MRT can be used to fix the training/test metric mismatch.
- Instead of maximizing log-likelihood of “gold” (real) training examples, sample hypotheses ỹ from the model during training and minimize risk.
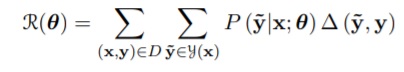
- The cost function is related to the actual translation metric.
Minimum Risk Training (MRT): The improvements
- The authors see an improvement in translation quality by 0.5 BLEU under MRT for IWSLT’14 DE→EN.
- From the manual evaluation results shown in the table below, it can be noted that MRT reduces the proportion of hallucinations on out-of-domain test sets.

Table 1: Proportion of hallucinations and BLEU on out-of-domain and in-domain test sets. DE→EN OPUS.
- Upon assessment of MLE and MRT scores for gold target sentence vs “distractor” sentence during beam search, the results show that MRT tends to increase the model’s certainty at later time steps, but importantly, the increase is sharper for the reference translations than for the distractors.
- The manual evaluation results in Table 2 shows that the proportion of hallucinations increases with beam size and that MRT consistently reduces the proportion relatively by 11-21%.
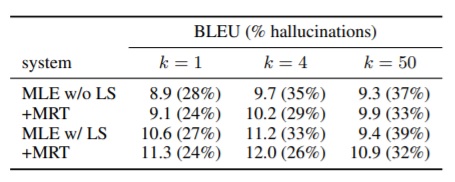
Table 2: Average OOD BLEU and proportion of hallucinations with different beam sizes k. DE→EN OPUS.
In summary
Wang and Sennrich (2020) establish an empirical link between hallucination and exposure bias. They show that training with Minimum Risk Training can improve the model robustness under domain shift, reduce the number of hallucinations substantially, and also help mitigate the beam-search problem.

Author
Akshai Ramesh
Machine Translation Scientist