

Introduction
Recent advances in multilingual natural language processing have shown progress in various tasks such as natural language inference and joint multilingual translation. But, despite this success, challenges arise where multilingual training regimes often boost performance on some languages at the expense of others.
In our soon to be published paper, “Language Clustering for Multilingual Named Entity Recognition” (Shaffer, 2021), we propose to address this issue by automatically grouping languages by similarity within a latent semantic space. Once these groups are discovered, we then train one named entity recognition model per language group and compare the results against three baselines, showing that our automatic clustering method outperforms baselines in the vast majority of the 15 languages studied here.
Sentence Encoding
In order to cluster languages together, we first need to obtain a representation for sentences that can be fed to a clustering algorithm. In the language of machine learning, we need a “vector representation” – a fixed-length list of numbers that represents the coordinates of each sentence in semantic space. So, how do we go about obtaining these vectors?
A common approach to this problem in NLP is to use a pre-trained language model to output these vector representations for sentences. This process is often called “encoding” – we feed in text, and we get out a vector. Once we have this general method in place, we need to choose a model for encoding. Luckily, the NLP community has a number of pre-trained models to choose from, including BERT and GPT-2. However, since our task is focused on multilingual data, we will utilize a similar model called XLM-Roberta (XLM-R) that is specifically pre-trained on 100 languages. This ensures that we will be able to encode sentences from a wide range of different languages in our experiments – not just English.
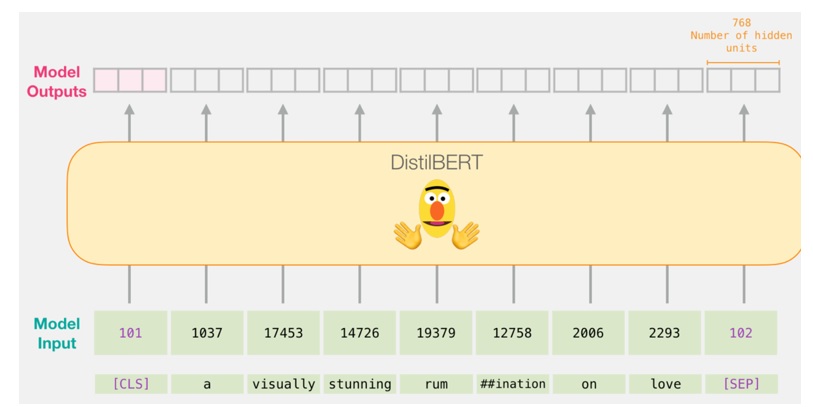
A high-level depiction of the encoding process (Credit: A Visual Guide to Using BERT for the First Time, https://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time/)
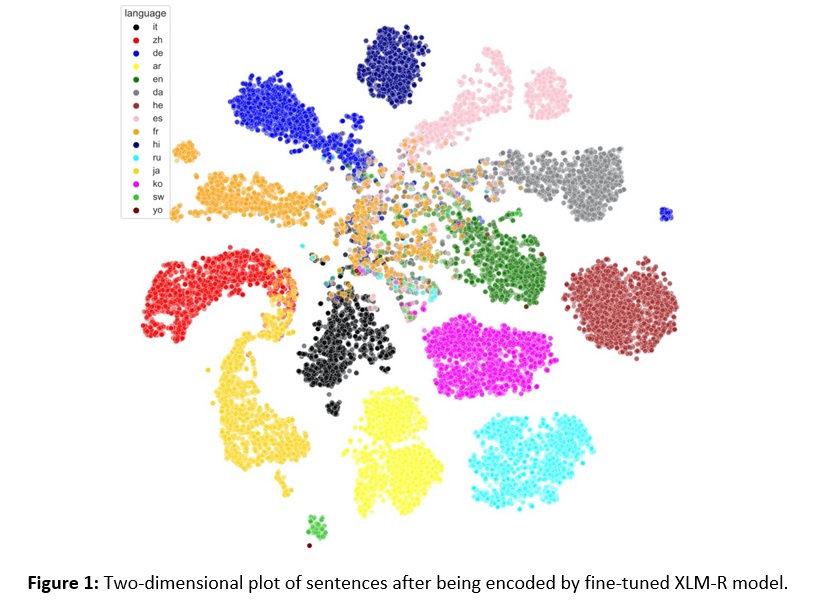
Prior work has shown that XLM-R provides strong encodings for many downstream tasks without further training or fine-tuning. However, in our experiments we found that fine-tuning this model on a language identification task greatly improved results. Figure 1 below shows how languages are clearly separated by the fine-tuned XLM-R model, and additionally displays intuitive overlap between some languages, such as that seen between Chinese and Japanese in the lower-left corner of the figure. The languages we used include: Italian (it), Chinese (zh), German (de), Arabic (ar), English (en), Danish (da), Hebrew (he), Spanish (es), French (fr), Hindi (hi), Russian (ru), Japanese (ja), Korean (ko), Swahili (sw) and Yoruba (yo).
Language Clustering
Once every sentence in the training set is encoded in this way, we can then group these vectors based on similarity to automatically discover language groups. We use a bottom-up clustering algorithm to group languages into four clusters, and these groupings are presented in Table 1 below.
We see confirmation of the qualitative overlap between Japanese and Chinese as shown in Cluster 4, and intuitive grouping of Indo-European languages shown in Cluster 2. However, we also note the surprising inclusion of Swahili and Yoruba in this cluster as well. This is especially interesting since these two languages contain the fewest number of training examples in the dataset, and this may raise questions about the robustness of this clustering technique. However, we will see later that this grouping helps boost performance when compared to three baselines.

Multilingual NER Tagging Results
Having obtained clusters for the 15 languages in our study, we can now train and evaluate NER models to test the effectiveness of this technique. We train and evaluate NER models on the WikiAnn dataset and evaluate using span-based F1 score as in the CoNLL evaluation. We initialize all NER models with XLM-R weights and fine-tune each model for 3 epochs with a batch size of 20 sentences.
For the clustering technique, we train and evaluate one NER model on all languages in each cluster and compare against the following three baselines:
(1) monolingual models trained for each language
(2) a single multilingual model trained on all 15 languages simultaneously, and
(3) a technique that uses linguistic family as the basis for grouping languages together.
We see in Table 2 below that our automatic clustering technique outperforms all baselines in the majority of languages and classes. However, we also see strong performance for the multilingual model (right-most column), especially in Arabic where it obtains best performance across all classes, though by a small margin.
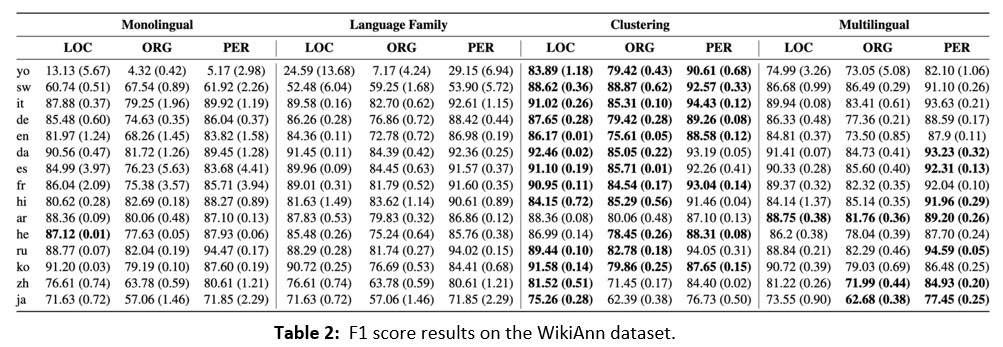
Looking at specific languages, we see quite low performance for the Yoruba and Swahili in the Monolingual setting, which is expected since these languages have the least amount of available data. However, we also see low performance when grouping them together in the Linguistic Family setting, with best performance resulting from our proposed clustering technique. This is encouraging and demonstrates that, despite the unintuitive grouping with Indo-European languages, the language clustering technique is helpful for multilingual NER despite not using top-down linguistic knowledge about these languages.
Zero-shot Analysis
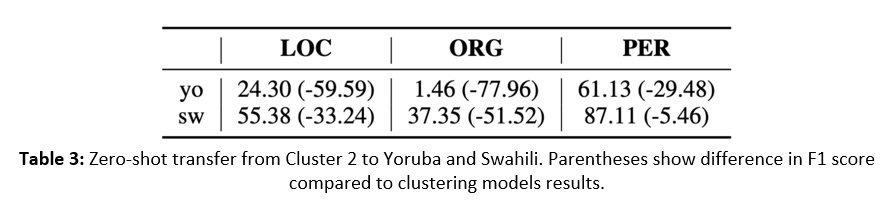
This last result regarding the Niger-Congo languages raises a question as to whether this improvement is due to effective learning of shared multilingual representations or whether it is primarily due to availability of more data of any kind. To test this, we evaluate NER models in a zero-shot framework where we train a multilingual model on all languages in Cluster 2 with Swahili and Yoruba removed and evaluate this model on these two held-out languages. These results are presented in Table 3 below. While we see that this transfer beats performance from monolingual models for some classes in these languages, we see that F1 scores for all classes are well below both the cluster models and the single multilingual model. This suggests that the increased performance on these languages in the clustering setting is due to advantageous multilingual transfer.
In summary
The results presented above indicate that using automated methods for clustering languages for multilingual named entity recognition retains good performance across languages that have sufficient data for training, while also boosting performance on low-resource languages.
Furthermore, we see evidence that these automated groupings are advantageous despite some counterintuitive language groupings, as in the combination of Indo-European and Niger-Congo languages. These methods can likely be extended to additional languages and could also generalize to other multilingual NLP tasks as has been seen in multilingual NMT (Tan et al., 2019).
However, these insights potentially extend beyond research. By improving performance on low-resource languages we have the opportunity to develop applications that help previously under-served users, and provide greater access to utilizing language technologies. We hope to expand upon this work with further research and integrate these advances into our products.
Tags:
Language WeaverAuthor
Kyle Shaffer
Research Scientist