
Introduction
Transformer has become one of the most commonly used architectures for building Machine Translation engines. It has led to a remarkable improvement in machine translation quality. In recent years, more and more attention is being paid to improving its efficiency, especially in the translation industry. In this post, we take a look at a paper by Lin et al. (2021) which conducts a series of experiments on different optimization methods over the standard Transformer-base model. By accumulating various strategies, they are able to achieve a 3.8× speedup on CPU and a 2.52× speedup on GPU with translation quality on par with the baseline.
Experiments
The experiments are designed to focus on three main aspects: Byte-Pair Encoding (BPE), Model Structure Updates and Training Strategies. They explored the impact of each method on the model efficiency, and tried to find a better optimization practice by accumulating different strategies together. All these methods are simple to implement and do not require hardware-dependent modification.
Byte-Pair Encoding
BPE has proven to be an effective tokenization strategy in handling rare words. However, as a side effect, breaking words into subword units brings longer sequences to process which causes negative impact on the efficiency. Applying more merge operations can shorten the sequence length, but the question is: How to balance the translation quality and the model efficiency? Lin et al. (2021) try with different BPE merge operations and compare their speed on CPU and GPU. According to the experiment result on WMT14 English to German data, instead of the default setting 32K, with 10K they already achieved a considerable speedup and even a slight improvement on the quality.
Model Structure Updates
Besides BPE merge operations, they also try to simplify Transformer by experimenting with different components in the decoder following the lead of some previous research (Kasai et al., 2020; Li et al., 2021; Voita et al., 2019; Michel et al., 2019; Hsu et al., 2020):
- Shallow Decoder, use only one decoder layer and add more encoder layers until the total number of parameters matches the baseline;
- Pruning Heads, only keep one head in decoder attentions;
- Dropping Feedforward Network (FFN), drop all FFNs in the decoder, with only attentions and layer normalization left in the model;
- Factorizing Output Projection, apply the low-rank approximation on the weight matrix following Lan et al. (2020) to reduce the number of parameters without seriously hurting performance.
Training Strategies
The simplified decoder as described above only retains about 0.3% of the overall parameters compared to the baseline. It helps to significantly reduce the computation cost, but also brings a negative impact on the translation quality. So in order to make the quality on par with the baseline, they try the following training strategies after the previous change of BPE merge operations and model structure updates:
- Deep Configuration, implement a deep model increasing the number of encoder layers following Wang et al. (2019);
- Weight Distillation (WD), initialize the student model with the corresponding weights from the teacher model as proposed by Lin et al. (2020), then continue the training of the student model as in standard knowledge distillation following Hinton et al. (2015);
- Weak Regularization, remove dropout in the decoder and also label smoothing as the decoder is already simplified a lot.
Results
Table 1 shows the results on WMT14 En-De data after accumulating each of the proposed strategies. According to the results, decreasing BPE merge operation from 32K to 10K slightly improves the speed and translation performance remains similar. Although decoder simplification significantly speeds up the efficiency, the translation quality, on the contrary, drops by 3.63 BLEU scores along with the accumulation of simplification methods. However, the following training strategies can make up for the performance loss and bring the scores back to a similar level compared to the baseline. The efficiency also gets further improvement up to a 3.8× speedup on CPU and a 2.52× speedup on GPU.
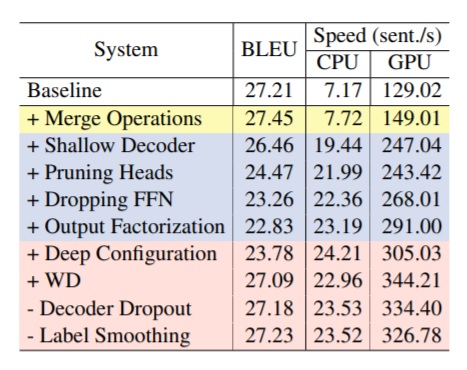
Table 1: Ablation study on WMT14 En-De. The colors refer to Byte-Pair Encoding (yellow), Model Structure Updates (Blue) and Training Strategies (Red).
In addition to the optimization experiments, Lin et al. (2021) also compared their simplified decoder network with some recent proposed methods (Zhang et al., 2018, Xiao et al., 2019 and Li et al., 2021) on three different language pair data sets: WMT14 English-German, WMT14 English-French, and NIST12 Chinese-English. Their approach consistently outperforms all other methods in terms of efficiency and obtains a translation quality very close to the others.
In summary
Lin et al. (2021) conducted a series of experiments on a Transformer-base model with different optimization strategies focusing on three main aspects: BPE merge operations, Model Structure Updates and Training Strategies. Their final method is able to speed up the inference efficiency by up to 3.80× on CPU and 2.52× on GPU without loss in translation quality by accumulating all strategies.
Tags:
Language Weaver
Author
Dr. Jingyi Han
Machine Translation Scientist