
Introduction
Writing involves a process of idea elaboration: an author starts with an outline of concepts and seams these concepts together to produce a cohesive text. One challenge of writing is in finding these connecting seams. What if linguistic AI and NLP could be used to help writers discover interesting connections between ideas? This is the broad question associated with our recent paper “Inspiration through Observation: Demonstrating the Influence of Automatically Generated Text on Creative Writing” (Roemmele, 2021). This work investigated a specific instantiation of this question, where ideas are represented by words and the task is to help people expand the words into a complete sentence. We refer to the task of transforming a list of words into a sentence as sentence infilling. We developed a language model to perform this task, and then examined how this model influenced people’s ability to do the same task on their own. We found that the model did indeed positively influence the writing outcome. Below I’ll describe more about the model design and the experiments that led to this finding.*
Sentence Infilling
Given a sequence of input words (e.g. “he, town, rain”), which we refer to as a “prompt”, the sentence infilling task expands the prompt into a full sentence by inserting (i.e. infilling) additional words (e.g.“he rode his bike to town in the pouring rain.”). Recent work has explored variations of this infilling task for creative text [e.g. Ippolito et al., 2019, Mori et al., 2020, Donahue et al., 2020]. Our infilling model is a Transformer language model (LM) initialized with pretrained GPT-2 weights [Radford et al., 2019], as represented in the figure below.
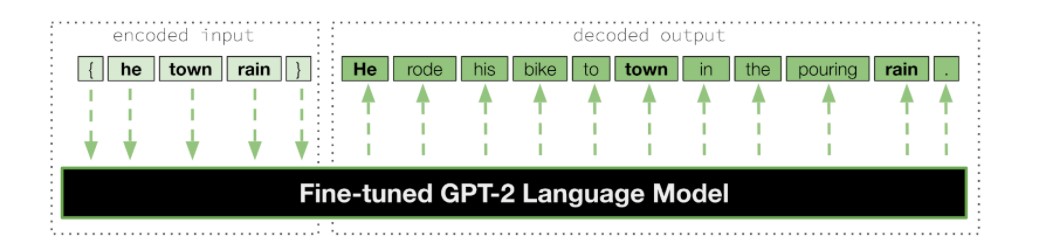
To train the GPT-2 model to specifically perform infilling, we fine-tuned it on a dataset of prompt-sentence pairs that we derived from 10K English-language stories in the BookCorpus [Kobayashi, 2018]. For a given sentence in this corpus, we randomly ablated a subset of its tokens. The ablated sentence became a prompt and its original form became the corresponding infilled sentence. Applying this to all sentences in the corpus resulted in ∼36M pairs, with ∼34M used for training, ∼1M used for validation during training, and the final ∼1M held out as a test set. We used the standard LM procedure of optimizing maximum likelihood estimation (MLE) loss to train the model, but we simulated an encoder-decoder scheme by only computing the loss for the target infilled sentences while omitting the loss of the source prompt tokens. For the experiment described below, we used the convention of autoregressive decoding to generate an infilled sentence for a prompt.
Authoring Experiment
We conducted an experiment where people wrote infilled sentences for a selection of three-word prompts from our test set. When selecting prompts, we hypothesized that certain prompts would be harder for people to infill than others, which could influence the role of the generated text in the authoring outcome. To examine this, we computed the average probability of the tokens in a prompt according to the DistilBERT LM [Sanh et al., 2019]. Prompts with high probability scores already resemble complete sentences, so we theorized that authors would write fewer infilled tokens for these prompts, thus requiring less authoring effort. Accordingly, we assigned the difficulty label “easy” to the 10% highest-probability prompts and the label “hard” to the 10% lowest-probability prompts. We applied our trained model to generate five infilled sentences for each of these prompts, using the decoding method of nucleus (top-p) sampling with p = 0.7.
We utilized these prompts and generated sentences in the human authoring task. In this task, participants were instructed that they would be shown a list of words (the prompt) and would write two unique sentences containing those words. The instructions emphasized that they should “try to write sentences that evoke a story someone would be curious to hear”. This guidance articulates the authoring objective of the task, which we refer to as storiability. Storiability is a construct that represents how appealing the sentences are to readers, which we ultimately evaluate as described in the next section. In the first stage of the task (the PRE stage), each author wrote two sentences for five prompts, which were randomly sampled from the “easy” and “hard” categories. In the second stage (the POST stage), authors were again shown the same five prompts and wrote an additional two unique sentences for each. This time, the five generated sentences were shown to them as examples they could reference while writing. 23 English-speaking authors recruited from Amazon Mechanical Turk (AMT) participated in this task. The result was a dataset of 109 authoring blocks balanced between easy and hard prompts. Each authoring block consisted of a prompt shown to the author, the two sentences they wrote before observing the generated examples (PRE), the two sentences they wrote after observing the generated examples (POST), and the five generated examples they saw (GEN). Below is an example of an authoring block.

Outcome
We then conducted a judgment task to evaluate readers’ perception of the sentences in the authoring blocks. We gathered judgment groups from the authoring blocks, where each judgment group consisted of a randomly ordered PRE, POST, and GEN sentence aligned to the same prompt and author. Raters observed these judgment groups and were told to “imagine that each sentence [in the group] is an excerpt from a story and pick the one that makes you most want to read that story”. This instruction is consistent with the objective of storiability that authors aimed for when writing the sentences. 16 AMT participants rated subsets of judgment groups, yielding a total of 1,744 responses. For our analysis, we labeled the sentence selected by the rater in each group as “Preferred” and the other sentences in the same group as “Not Preferred”.
Here is the resulting distribution of preferences:

These numbers indicate that while raters dramatically preferred human-authored sentences over the generated ones, they favored the sentences people wrote after observing the generated examples (POST) compared with those written before (PRE). One caveat is that this pattern was only statistically significant for prompts with a “hard” difficulty level. Here are the preferences for the human-authored sentences separated by difficulty level:

As mentioned above, we expected that sentences for hard prompts would contain more infilled tokens compared to easy items, and indeed this was the case:

Altogether this suggests that observing the generated examples was more impactful when more authoring effort was required. Thus, we focused our subsequent analyses on the hard items. We used DistilBERT to measure the vector cosine similarity between the authors’ sentences and the corresponding generated examples they saw. We found that the similarity between the POST and GEN sentences was higher than the similarity between the PRE and GEN sentences:
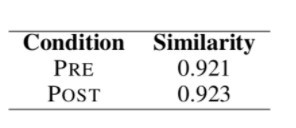
This difference was statistically significant, which confirms that authors were influenced by the content in the GEN examples. Moreover, POST sentences preferred as more storiable were also more similar to the GEN examples:

This difference too was statistically significant, which means that authors tended to write more storiable sentences when they derived more content from the generated examples. This ultimately shows that these examples helped authors better perform the writing task.
We regard these findings as evidence of an “inspiration through observation” paradigm for human-computer collaborative writing, through which human writing can be enhanced by text generation models without directly copying their output. We know that authors did not simply mimic the generated examples: if they had, there would not have been a significant difference in storiability between the POST and GEN sentences as reported above. More research is needed to understand the exact mechanism by which the generated examples influenced the authors. There is some qualitative evidence that the examples helped people discover new connections between the prompt words, in line with the broader motivation of this work. In particular, GEN examples may have revealed a semantic dimension by which the prompt words were related, one that authors did not initially consider in the PRE condition. This item from one author in our experiment suggests this possibility:

The GEN example connects the prompt words “shoulders”, “waves”, and “color” through the conceptual dimension of “hair”. The author’s POST sentence similarly mentions hair, which the author did not reference before seeing this generated example. We can speculate that the example triggered the author to recall that the prompt words could be unified through this concept, and they emulated this connection in the POST sentence.
In summary
Even though the experiments in (Roemmele, 2021) focused on one particular authoring task (sentence infilling) and one particular way of evaluating the outcome (storiability), other research could explore this same “inspiration through observation” scheme for other forms of writing and desired objectives. This can be applied to building interactive systems that help people turn fragmented ideas into elaborate narratives. These systems have the potential to expand human thinking without compromising or replacing the human nature of creativity.
*All code associated with our model and experiments, as well as the data resulting from the experiments, is available at github.com/roemmele/InSentive.
Tags:
Language Weaver
Author
Dr. Melissa Roemmele
Research Scientist