
Evaluating linguistic novelty in text generation using RAVEN
Introduction
Neural language models (LMs) such as GPT-2 are good at producing fluent, reasonable-sounding text. The question is whether the rich, human-like text is generated by the deep models with learned complex linguistic knowledge, or is it just stochastic parrots training data? The answer is some of both. In this post, we'll discuss How much do language models copy from their training data? Evaluating linguistic novelty in text generation using RAVEN by McCoy et al. (2021). The authors try to answer how "deep" deep learning is in the case of open-ended text generation by evaluating the novelty of generated text using n-grams and syntactic structures.
Natural Language Generation (NLG) Evaluation and Novelty
NLG evaluation is marked by a great deal of variety to assess text quality, such as a holistic score to evaluate n-grams overlap with one or multiple references such as BLEU and CIDEr, or multiple scores for assessing different aspects of outputs such as fluency (Mutton et al., 2007), coherence (Lapata and Barzilay, 2005), or factual accuracy (Kryscinski et al., 2020). However, evaluating generated text alone cannot determine if it is generated by the model or copied from training data. This question is essential as quality on its own cannot reveal too much about an NLG model’s learnability. Therefore, the authors propose to disentangle these possibilities and evaluate the novelty of generated text. The paper focuses on surface-level novelty— a generated structure as duplicated if it appears in the training set or the context (the concatenation of the prompt and the text that the LM has already generated based on the prompt); otherwise, it is novel.
Experiments
The authors use three models (LSTM, Transformer, Transformer-XL) trained on Wikitext-103 to get a systematic comparison. In addition, they also use GPT-2 trained on WebText as a larger model for analysis. They introduce 1000 prompts of length 512 words for Wikitext-103 and the same number of prompts of size 564 sub-words of WebText to let the models generate the following 1000 words or 1100 subword tokens. To propel the model to create high-quality text, the decoding method they use is the top-40 sampling, the same setting as in Radford et al. (2019) and Dai et al. (2019). Human-generated text is analyzed as the baseline. All the models generate novel n-grams, morphological combinations, and syntactic structures, and we will further discuss them in detail.
N-gram novelty
For all n-grams generated by LMs of size 5 or larger, most n-grams are novel. Figure 1 shows the proportion of generated n-grams that are not shown in the training set (0<n<11). Moreover, n-grams generated by LMs are rarely novel for small n. For example, the baseline (human-generated text) has 6% new bigrams, while the LSTM, Transformer, and Transformer-XL models only show 2% to 3% novelty in the 2-gram case. When n is larger, the LMs are slightly more novel than the baseline. The same tendency holds in the GPT-2 case on WebText data. Another interesting observation is that LSTM is the least novel for small n-grams, while Transformer is the most novel, and Transformer-XL falls in-between.
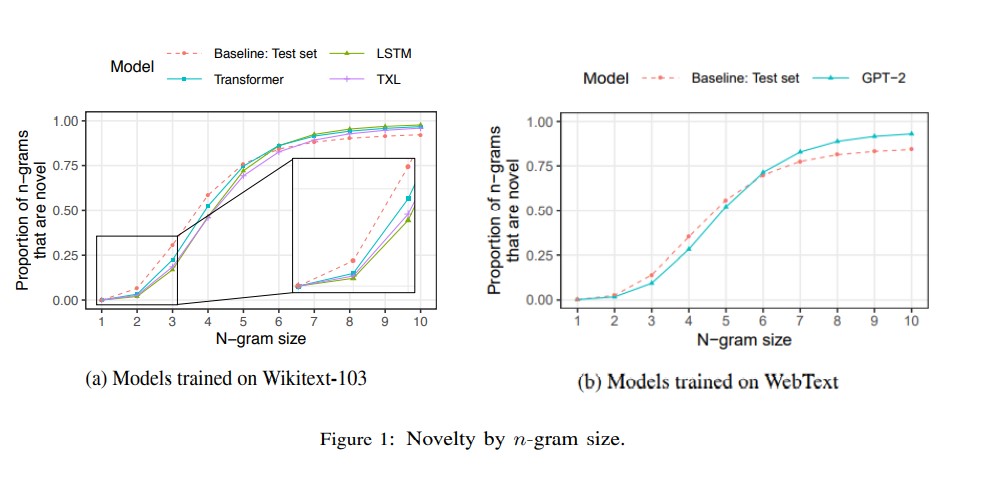
In terms of copying, although all LMs rarely duplicate n-grams larger than 10, all models occasionally copy training set passages that are 100 words or longer. The authors use the term “supercopying” to refer to this long string duplicate phenomenon and hypothesize it is caused by multiple occurrences of the repeated long sentence in training data. In addition, experiments show that changing decoding parameters can alter the quality of generated text and thus further influence a model’s novelty.
Syntactic novelty
The authors evaluate syntactic novelty in terms of global and local structures. The global structure includes the part-of-speech sequence of words in the whole sentence and the sentence’s constituency tree minus the leaves. Local structures cover dependency arcs and roles. The former one refers to a 3-tuple of dependency relation and the two words that hold that relation, e.g. (“this”, nsubj, “is”) in Figure 2. Like dependency arc, dependency role refers to a 3-tuple of a word, a dependency relation that the word is part of, and the position of the word in that relation, e.g. (“is”, nsubj, head) in Figure 2.

At the level of global structure, LMs show a high degree of syntactic novelty, with the majority of generated sentences having an overall syntactic structure that does not occur in training. However, for local structure, the LMs are less novel than the baseline.
Human evaluation
The manual evaluation part focuses on the most powerful LM GPT-2. By using subword tokenization, it can generate new words by combining seen subwords in a new way, including inflections (e.g. Swissfied), derivations (e.g. IKEA-ness), and acronyms (e.g. West of England Cricket and Athletics Club (WECAC)). The authors are interested in exploring whether these newly generated words are morphologically well-formed and fit the syntactic context. For the labor-intensive nature of this task, this paper limits the scope to evaluate unigrams only. The results show that 96% of the new words are well-formed, and 94% are used grammatically correct in context. In contrast to GPT-2’s success in creating morphological and syntactic sound text, the generated words do not have reasonable meaning in some cases.
In summary
The core message of this paper by McCoy et al. (2021) is that novelty is an essential aspect of NLG evaluation that should be receiving attention. Without a novelty check, the assessment of NLG output quality, such as grammaticality and fluency, may not hold if the “generated text” is copied from a training set. The authors introduce using n-grams and syntactic structures to evaluate novelty. Their results show that LMs are always novel in larger-scale structures but less novel in local structures.

Author
Dr. Yiyi Wang
Research Scientist