
Introduction
Consider translating the sentence “I stood at the bank”. How should we translate the ambiguous word, bank? We might have access to a cue – a sentence related or similar to the input. The translation will likely be different if the cue is “I was at the river”, compared to the cue “I was depositing money”. This is an example of priming a translation.
Recent efforts to prime machine translation include work by Bulté & Tezcan (2019) and Xu et al. (2020). In both cases the system is given a translation of a cue to use when generating its own translation. In this post, we look at the paper by Pham et al. (2020) proposing a different approach, priming MT with both a similar input and its translation.
How to prime
There are two main steps to the process: finding sentences that are similar to a given input, and then priming the translation for that input using the similar sentences.
Finding similar sentences
The authors explore three ways to find similar sentences for priming:
- Fuzzy Matching: Similar sentences have a small edit distance with the input.
- Sent2Vec (S2V): Similar sentences have a high embedding cosine similarity with the input. Sentence embeddings are the average of embeddings for all bigrams.
- Continuous Bag of N-grams (CBON): As Sent2Vec, with sentence embeddings averaged over embeddings for all n-grams up to arbitrary n.
These techniques find similar sentences in the source language. Assuming we have parallel training sentences, we can then take the corresponding translation for a similar sentence, resulting in a priming pair.
Priming with similar sentences
Once we have k similar sentences and their translations, we can use them to prime the MT system. The authors explore two previously proposed methods which integrate only the translations of similar sentences. They then propose a new approach which uses the similar input sentences and their translations as cues.
Say we want to translate the English phrase “flu vaccine” into French. We may find the related phrase “measles vaccine” in our dataset, with corresponding translation vaccin contre la rougeole. The cue can be used as follows:
- tgt follows Bulté & Tezcan (2019). The input sentence is simply preceded by one or more similar translations, changing what is fed to the NMT model:

- tgt + STU, proposed by Xu et al. (2020), addresses the fact that models trained with tgt may tend to copy unrelated words from the cue. It marks each input token as a source language token (S), relevant target language token (T) or an unrelated target token (U). In this example, rougeole, measles, is unrelated:

- s+t, proposed in Pham et al. (2020), uses both sides of the priming pair. Similar source sentences precede the sentence of interest, and the model decodes the similar translations as a prefix before producing a translation. The MT system effectively translates a related sentence with guidance before translating the real input:

Experiments
Setup
The authors experiment with English-French translation across eight domains, including Wikipedia, political, news, IT, medical, legal and financial text. They train Transformer models for each scheme on the concatenation of datasets across all domains, holding out 1000 random sentences for testing for each domain along with any duplicates of the test data. They mine similar sentences and their translations from the training data.
Importantly, we may not always find similar enough sentences to usefully prime the model. The authors only include similar sentences when their fuzzy matching score is at least 0.5, or when their cosine distance from the input is at least 0.8 for the embedding metrics.
Assessing priming schemes and similarity schemes
The authors first compare priming schemes. They allow at most one priming example extracted using fuzzy matching, so all methods use exactly the same priming examples. Priming with tgt improves over the baseline by 4.5 BLEU on average across all domains. Adding the STU annotation gives an additional 1 BLEU improvement. In this setting the s+t scheme outperforms tgt+STU by approximately 0.3 BLEU on average, but performs similarly overall. Improvements for each domain correlate strongly to the proportion of test sentences where a fuzzy match was found.
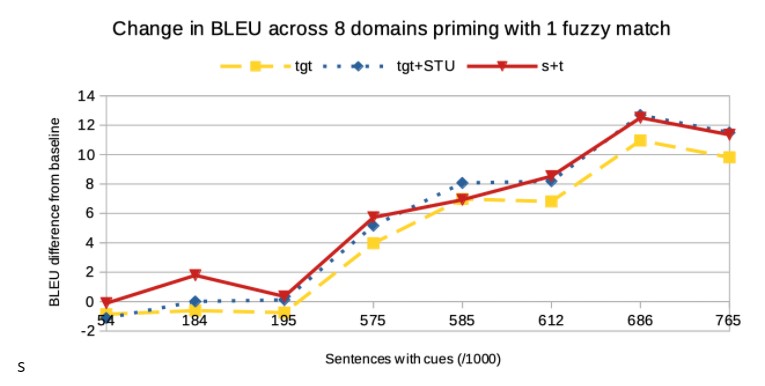
The authors then assess s+t using the embedding schemes, finding slightly better results than fuzzy matching with CBON and slightly poorer results with S2V. They note that their fuzzy matching scheme only returns one match per sentence pair, while the embedding similarity measures can return multiple cues.
Comparison to fine-tuning on similar sentences
The authors compare against a fine-tuning approach inspired by Farajian et al. (2017), previously discussed in the Neural MT Weekly #19. Farajian et al. (2017) propose briefly fine-tuning a model on a set of similar sentence pairs for each input. The authors replicate their basic approach with fixed hyperparameters using the sentence pairs extracted by fuzzy matching and CBON. They find average improvements of 2 BLEU when tuning on fuzzy matches or 2.5 BLEU on pairs found with CBON – a noticeable improvement but significantly less than the 6 BLEU increase when priming with s+t and CBON.
Unrelated words in priming sentences
A downside of tgt – the simplest priming scheme – is that the model cannot easily distinguish between related and unrelated words in the cues. Unrelated words from the cues may end up being copied into the output. Using the above example, the system might over-rely on the priming example and simply translate “flu” into rougeole, measles.
The tgt+STU scheme was designed to mitigate this effect. The authors find on average tgt+STU reduces copied words in the output by about 8%. Their new scheme, s+t, reduces the number of copied unrelated words by a further 8% relative to tgt+STU, without having to identify related and unrelated words.
Priming with synthetic source sentences
We may have trouble finding in-domain sentence pairs that are similar to the test inputs. This is a problem, as the authors find the domains which benefit from priming are those where the most priming pairs can be found.
It can be easier to find in-domain target language sentences. We can back-translate these to produce synthetic source language sentences, as proposed by Sennrich et al. (2016). This expands the set of available priming pairs.
The authors take this approach for the News and Wiki domains. Scores improve over the parallel-only setting by almost 2 BLEU for Wiki, where synthetic-source cues are found for an additional 9% of the test set. However, the News set still does not have enough good priming examples to outperform the baseline.
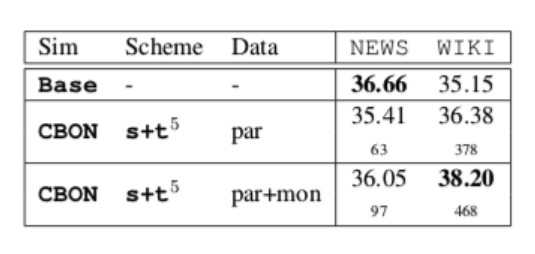
The authors also note that priming with synthetic sentences can introduce noise, and may not be beneficial when parallel matches are available for a given input sentence.
In summary
Priming with related inputs and translations is an intuitive way to incorporate terminology or domain knowledge into machine translation. Pham et al. (2020) demonstrate that priming neural machine translation can be very effective. They also explore how the methods for obtaining and incorporating priming sentences can affect performance across a range of domains.

Author
Dr. Danielle Saunders
Research Scientist