
Introduction
Natural language processing has seen an explosion of progress thanks to wide availability of large pre-trained language models (LMs). These models are often taken as a strong starting point for a downstream NLP task (such as named entity recognition or sentiment classification) and fine-tuned on relevant data with the appropriate objective function. However, despite the advantages of this approach, fine-tuning these LMs can often be time consuming and computationally expensive.
Adapters (Houlsby et al., 2019) were developed to accelerate training by introducing a small number of additional weights that are updated during fine-tuning of the LM, leaving the original weights frozen. While there has been discussion of the practical advantages of decreasing training time with this approach, there has been less work investigating the empirical performance of adapters compared to traditional fine-tuning. That is, while previous research has mainly focused on training efficiency, most of this work has not investigated how adapters compare to fully fine-tuned models.
In this post, we look at the work by He et al., 2021 “On the Effectiveness of Adapter-based Tuning for Pre-trained Language Model Adaptation”, where they investigate this issue in detail, showing that adapters are competitive with their fine-tuning counterparts, while often outperforming traditional fine-tuning in small data scenarios and cross-lingual applications.
Adapters
Adapters were introduced as an alternative method for fine-tuning pre-trained neural LMs such as BERT (Devlin et al., 2019) or GPT-2 (Radford et al., 2019). Instead of allowing all weights in a model to be adjusted to a downstream task, adapters introduce a small number of additional parameters and only these parameters are updated during fine-tuning. An overview diagram is presented in Figure 1 below.
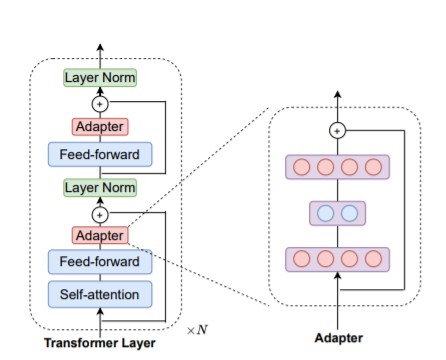
Figure 1: Depiction of adapter weights – from He et al.,2021 paper.
While this method slightly increases the overall size of the model by introducing additional weights, training on downstream tasks typically progresses much more quickly since only these newly introduced weights are updated. This technique also ensures that weights learned in the pre-training step are not completely overwritten during the fine-tuning phase – an issue in transfer learning often referred to as “catastrophic forgetting” (McCloskey and Cohen, 1989).
(He et al., 2021) conduct experiments to further analyze the performance of adapters compared to standard fine-tuning in which all model parameters are updated. In particular, the authors present the following findings:
- In monolingual settings, adapters can outperform standard fine-tuning in low-resource data settings, and mostly match fine-tuning in high-resource settings
- Adapters outperform fine-tuning in cross-lingual zero-shot settings
- Additional analysis shows that adapters are more stable than fine-tuning and are less susceptible to overfitting than fine-tuning
Experimental Setup
To compare adapters against standard fine-tuning the authors run experiments in two settings: (1) tuning pre-trained LMs to different downstream domains in both low- and high-resource data settings and (2) evaluating both methods in a cross-lingual zero-shot framework (e.g. fine-tuning a model on English and evaluating on German).
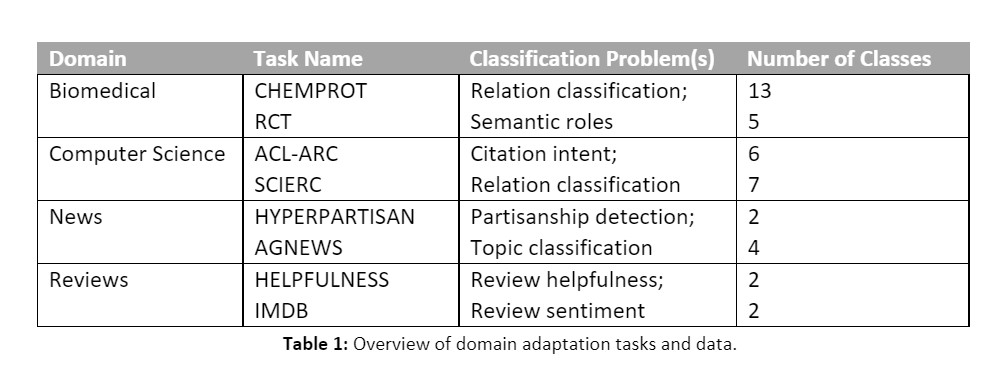
For domain adaptation experiments the authors focus on the following data domains and modeling problems outlined in Table 1 below. To simulate low-resource settings, the authors sample 5,000 training samples from each data source and evaluate on the full test set. All models for these experiments are initialized from Roberta-base (Liu et al., 2019).
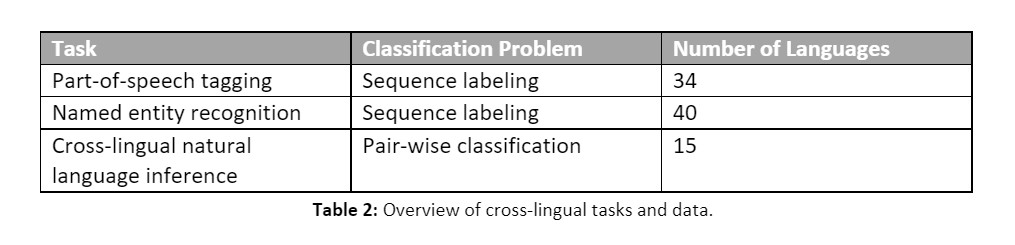
For cross-lingual experiments, authors investigate subsets of the XTREME benchmark dataset (Hu et al., 2020). An overview of the data used is provided in Table 2 below. Weights for these models are initialized using XLM-Roberta-Large as their starting point (Conneau et al., 2020).
Results
Domain/Task Adaptation
For the monolingual experiments, the authors present results in both low- and high-resource settings as shown in Figure 2 below. Focusing on the low-resource setting (three left-most columns) we see that the adapter-based tuning outperforms full fine-tuning in all cases by roughly 2 F1 points. This suggests there is an advantage to keeping many of the original weights in the pre-trained LM for lower resource tasks where model training may become unstable due to updating on very few training examples.
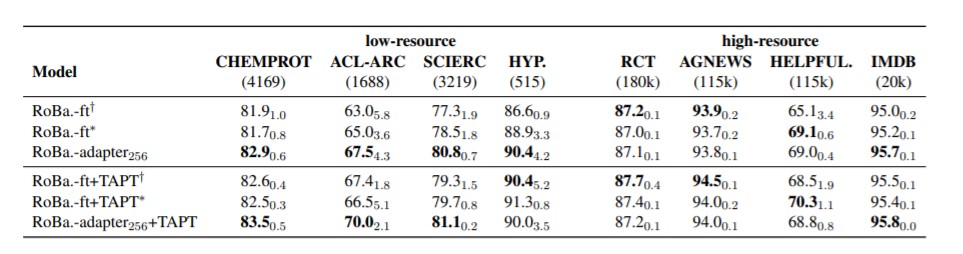
Figure 2: Monolingual results (average F1 score) for domain/task adaptation experiments.
For high-resource settings (right-most three columns), we see adapter-based tuning does not outperform fine-tuning in most cases. However, even in these cases, results are very competitive with the full fine-tuning results. This provides further evidence that even in high-resource settings adapters retain most of the performance of their fine-tuning counterparts while having to update only a fraction of the parameters.
Further experiments show that at varying numbers of training examples, adapters consistently outperform fine-tuning across many low-resource scenarios. Figure 3 below shows that for the RCT and AGNEWS datasets adapters consistently outperform fine-tuning when there are 8,000 or fewer training examples. As the amount of available training data grows, there is little difference in performance between the two methods, however adapters are consistently competitive with fine-tuning.
Cross-Lingual Adaptation
In the set of cross-lingual experiments, the authors also present strong results from adapters, showing that they outperform fine-tuning in all cross-lingual tasks. These results are summarized in Figure 4 and show three settings per task. All models are tuned on English-only data, and then evaluated on various other languages. In the All setting, the model is evaluated on all available languages, Target is evaluated on only non-English target languages, and Distant is evaluated only on languages that do not belong to the Indo-European language family and are thus considered linguistically “distant” from English.
Even in the case where the models are evaluated only on languages considered to be most dissimilar to English (Distant) adapters outperform fine-tuned models on all tasks, sometimes by over 3 accuracy points (POS tagging). This demonstrates that even in tuning scenarios where ample data is available, adapters show impressive performance in handling multiple languages for various downstream tasks.

Figure 4: Cross-lingual results on POS tagging, NER tagging, and XNLI classification.
Overfitting and Regularization
In addition to the above experiments, He et al., 2021 also analyze how adapters affect the stability of training. To do this, they track loss on a held-out evaluation set over a large number of training iterations and compare adapters to fine-tuned models. In Figure 5 below, we see loss curves plotted for fine-tuned models (blue) and adapter tuned models (orange) across four different datasets. In each case, the held-out loss for adapters is markedly lower than the corresponding fine-tuned model loss.
Perhaps more interesting is the flatness of the adapter curves for the QNLI and SST-2 datasets (right-hand side of Figure 5). These curves show that even over many update steps, the held-out loss increases at a very slow pace compared to traditional fine-tuning. This suggests that fine-tuning with adapters may serve as a strong form of regularization since relatively few weights are being tuned to the downstream task compared to the number of weights in the pre-trained LM.
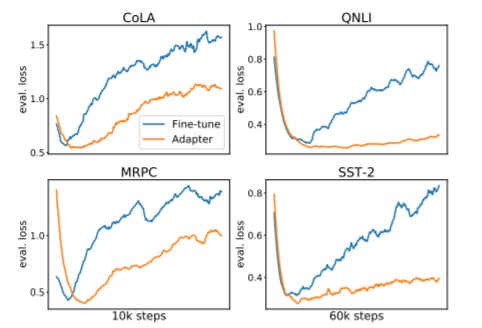
Figure 5: Loss curves over held-out evaluation sets showing how adapters are more robust to overfitting.
In summary
He et al., 2021 investigate the empirical performance of adapters compared to standard fine-tuning. The results presented suggest that adapters are better suited to fine-tuning on small amounts of data while retaining strong performance. Cross-lingual experiments also show that adapters are perhaps better than standard fine-tuning in zero-shot applications across many different languages. Finally, the authors present analyses suggesting that adapters may provide advantageous regularization for some tasks, making training for long periods of time more stable and less prone to overfitting. These results, coupled with the training efficiency demonstrated in previous work, make adapters an extremely valuable method for fine-tuning pre-trained LMs on downstream tasks.

Author
Kyle Shaffer
Research Scientist