
Introduction
For decades cognitive scientists and linguists have been using color as a tool to analyze language systems. Since the perceptive color spectrum is considered a shared experience across languages, it is often used to compare how languages divide the same spectrum into different concepts. This has been vastly studied in Brent Berlin and Paul Kay’s research Basic Color Terms: Their Universality and Evolution in 1969 and the many papers that followed it.
So it came as no real surprise to see two papers at EMNLP ‘21 studying color in language models. That is, until you realize they have seemingly contradictory conclusions on the capability of language models to understand color. In today’s blog post, we discuss their results and what they can show us about language models.
The World of an Octopus: How Reporting Bias Influences a Language Model’s Perception of Color
Paik et al. (2021) researched if pre-trained language models accurately encode color, given the reporting bias in the text datasets they’re trained off of.
Reporting bias, in this case, refers to people’s tendency to specify details only when they deviate from expectations. For example, a recipe may call for a “brown” or “green” banana, but the rest will call for simply “bananas” assuming you know they should be yellow. Since underripe or overripe versions diverge from the stereotypical image of a yellow banana, the speaker marks the distinction with a modifier, like the adjective “brown.” This tendency in language can lead to reporting biases in datasets, where atypical or unusual objects and events get mentioned more frequently than common ones.
Given this bias, Paik et al. investigated if such data has also skewed language models for what colors objects most often are. To establish a real-world probability of an object’s color, they had human annotators score the likelihood of 521 objects being any of 11 colors. The resulting color distributions were split into three groups: objects that are commonly a single color, multiple, or any color. By placing each of their colors into sentences like “Most bananas are [color].” and ranking a language model’s probability for the sentences, they could measure the model’s color probability distribution and how it correlated with their human-ranked dataset and with text-based Ngram color distributions from Google Books Ngram Corpus and Wikipedia. 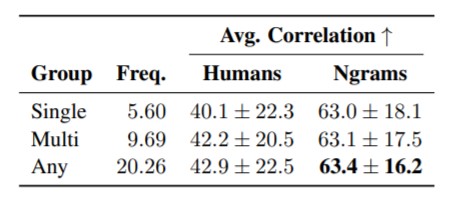
The average results across the 14 models (various sizes of GPT-2, RoBERTa, and ALBERT) show the effect of the reporting bias in that every color type has a higher correlation with the color distribution found in texts rather than the human-made distributions of real-life experiences. The authors also note a likely cultural bias in the human annotations, who were all based in the United States. Further research with a cross-cultural and lingual approach could prove enlightening.
Can Language Models Encode Perceptual Structure Without Grounding? A Case Study in Color
While Paik et al. (2021) comes away suggesting text-based language models do not represent what color objects truly are in the world, Abdou et al. (2021) has a warmer verdict for language models’ color representations, in that their color embedding space can be similar to the actual color spectrum we perceive.
Since pre-trained language models can embed concepts with relational reasoning (e.g., the sum of vectors “France” and “Capital” can be similar to the vector “Paris”— you can learn more with Issue #24), the authors investigate whether the relative spacing for color embeddings could be significant. To do this they created two different spaces, one for our color perception and one for language models. By using 18 color name judgements on a data set of 330 color chips and mapping them onto color axes from CIELAB, they made a three-dimensional mapping of color, with each labeled color chip acting as a point in space. 
To create a corresponding space representation from language models, the authors placed their 18 color names into three controlled-context templates (e.g., “the [obj] is [color]”) using a list of 122 objects. The resulting sentence embeddings gave them 366 points in the language model embedding space to refer to each color. Using an approach described in Lindsey and Brown (2014), they calculated the center of each color region in both spaces, visualized below: 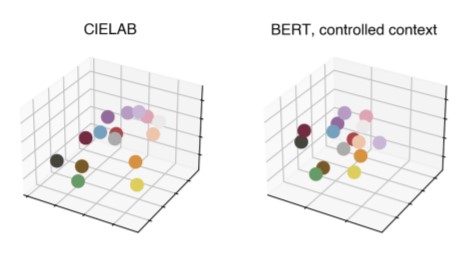
By using Representation Similarity Analysis, a non-parametric method that computes representational similarity matrices, the two distributions of the color centers could be compared for correlation across spaces. Linear regression was also utilized to verify to what extent these embedding spaces could be mapped to each other —which had relatively high results even for their baseline model with word-type FastText embeddings trained on Common Crawl. 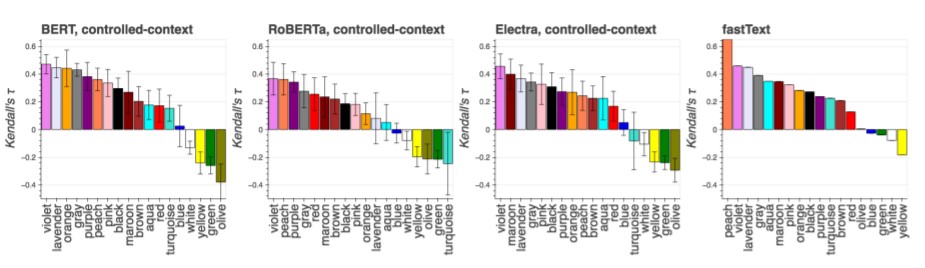
As seen in the graphs above, not only do the models tested have significant correlation with many of the real-life perceptive colors but they also have similar color patterns across models. To further study this trend, the authors break their colors into warm and cool tones: 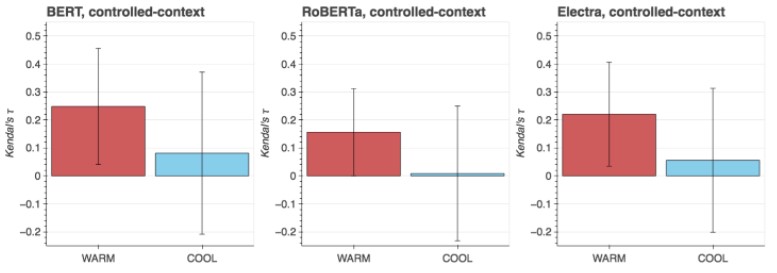
Across all models and context types studied, warm colors have a higher correlation with the CIELAB color space than cool ones, which the authors note relates to research about languages being more efficient communicating warm colors compared to cool ones (Gibson et al. 2017). They further research the predictive factors for color correlation to discover that colors often used as adjectives correspond to closer alignment, while colloquial color usage (e.g., “Black Death”) corresponds with weaker alignments to the CIELAB space.
In summary
Although Paik et al. (2021) and Abdou et al. (2021) ultimately contradict each other on how effectively language models represent color, they support each other in more ways than meets the eye. Both demonstrate how well language models can build conceptual structures to match the information presented just in text-based data. However, both papers also demonstrate how much influence the pragmatics and syntax in training data have on a language model. For Paik et al., a pragmatic maxim to not include unnecessary information has led to language models being less representative of color distribution in the world. Abdou et al. reveal language models can produce color mappings that are similar to reality, but also that their performance has lower correlations depending on how color is used syntactically and colloquially in text.
While the perception spectrum provides a handy ground-truth line to measure language models against, these effects likely apply to more domains than just color. For example, reporting bias also appears in how “male nurse” is currently 3 times more common than “female nurse” in Google’s Ngram data. As we utilize and develop language models more in the future, we all can benefit from a better understanding of what we’re unintentionally training into our models along the way.

Author
Katrina Olsen
Research Engineer