
Introduction
The latest neural machine translation (NMT) technology has brought translation quality to the next level. There has been a lot of effort in trying to alleviate the problem with low resource languages, assuming that with a good amount of parallel data, most of the issues that harm the translation quality will be solved. However, numerical mistranslation seems to be a very common but challenging issue for both high- and low-resource language situations. Those widely used evaluation metrics such as BLEU, COMET and METEOR are not enough to highlight numerical translation errors. In this post, we take a look at a paper by Wang et al. (2021) which extends the CheckList proposed by Ribeiro et al. (2020) to evaluate several fundamental capabilities a NMT system should be expected to exhibit in translating numbers.
CheckList Methodology
The original idea of CheckList by Ribeiro et al. (2020) includes a matrix of general linguistic capabilities and test types that facilitate comprehensive test ideation, as well as a software tool to generate a large variety of test cases quickly. In this paper, Wang et al. (2021) adopt this idea to test the capabilities of handling four types of numerical translation issues in NMT:
- Integers: sequences of digits with variable lengths.
- Decimals: decimals with the decimal mark placed at varying locations.
- Numerals: numbers that are presented as words.
- Separators: numbers containing decimal or thousands separators.
To test each type of issue, they create a list of sample sentences with numbers that could be taken from various sources like existing corpora or manually crafted. Then these samples are generalized into templates by replacing numbers with formats of different lengths and decimal-point positions. For example, one format could be “ddd.ddn”, which consists of multiple digits and a numeral such as 100.01 million. Each format is filled with random digits and numerals. In total, 25 different formats are tested across all issue types. To evaluate the translation performance on numbers, they translate those sentence samples and report the pass rate (PR) on the correct numerical translations compared to the source side.
Experiments and Results
The experiments are conducted on four different language pairs (both directions): English -German (En-De) and English-Chinese (En-Zh) for high-resource scenarios and English-Tamil (En-Ta) and English-Nepali (En-Ne) for low-resource scenarios. They translate the test samples with engines from two popular commercial MT providers (A and B) and also top ranked engines (En-De engine by Ng et al., 2019, En-Ta by Chen et al., 2020, and En-Zh/Ne by Fomicheva et al., 2020) in WMT competitions (R). The final results are reported in Table 1. 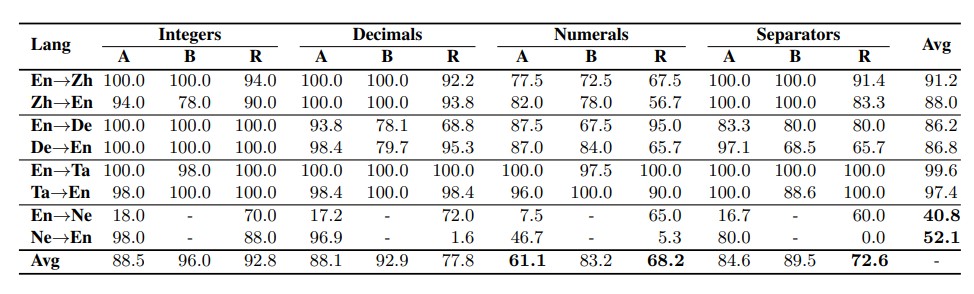
Table 1: Test results (PR %) on the capabilities for numerical translation, with low averaged scores in bold. Nepali is not supported by System B.
The evaluation is able to show to what extent NMT systems can well handle those number mistranslation issues. In general, the performance of the engines from A, B and R are in line. Here is a summary of those common errors across all systems:
- Integers are relatively the easiest issue to handle. However, NMT systems show the difficulty of handling repeated digits: they might omit or add one or more digits in the translation compared to the source side.
- Separators could be trouble in localization usage for those language pairs that do not share the same use of symbols like the case of En<->De ( “,” and “.” are the thousands and decimal separators in English, but the other way around in German). Besides, sometimes systems are prone to translate decimal numbers into wrong digits, and this error might be related to the separator confusion according to the result from En<->De.
- Numerals are the most challenging issue across all systems for most of the language pairs. This is reasonable as numbers are less frequently written in words, which results in insufficient training examples available for training.
- Translating numbers accompanied by unit words (e.g., million and billion) could be difficult for those language pairs that do not share the same units of measurement (e.g., “10.01 million” into “1001万” in Chinese). Systems may fail to convert numbers to the correct target unit.
- Results from low resource language pairs are not always worse than that from high-resource ones. As shown in Table 1, En-Ta is surprisingly one of the best across all test types. This suggests that the size of training data is not the sole factor for high-quality numerical translation.
- In the case of En->Ne, the results across all capabilities are far from satisfactory, this is probably because Nepali has its own numerals for digits. In a low resource scenario, the conversion into Nepali digits becomes a big challenge.
To mitigate these numerical mistranslation problems, Wang et al. (2021) also discuss several potential strategies, such as Separating numerical translation out into an individual process as in Statistical Machine Translation; adding more quality numeral-specific instances into training data; and forcing to encode all numbers as character sequences or meaningful groupings of components, since BPE often split long sequences of numbers into different tokens.
In summary
Wang et al. (2021) extend the CheckList methodology by Ribeiro et al. (2020) to systematically assess four fundamental capabilities (Integers, Decimals, Numerals and Separators) of NMT systems in handling numerical translations for both high- and low-resource cases. They point out several common types of errors across all evaluated systems and also provide a detailed error analysis on them. The potential mitigation strategies they discuss could be useful for such numerical translation improvement.

Author
Dr. Jingyi Han
Machine Translation Scientist