
Introduction
Neural Machine Translation (NMT) models are often trained on heterogeneous combinations of data from multiple domains, typically not balanced or diverse with respect to domain. This results in the NMT model performing well on the high-resource domains but poorly on the low-resource ones. Ideally, a multi-domain NMT model should be able to perform well across all the constituent domains. In today’s blog post, we will take a look at the work of Currey et al. (2020) who propose a new approach called Multi-Domain Knowledge Distillation (MDKD) that can be used to train a single multi-domain NMT model to translate several domains without increasing the inference time or memory usage.
The Approach
The authors generalize the previous work of sequence-level knowledge distillation (Kim & Rush, 2016) to the multi-domain scenario by distilling the output of multiple domain-specific teachers. The proposed approach consists of 3 main steps:
i) Train domain-specific teacher models:
- The concatenated data from all domains is used to train a deep generic model.
- Create separate teacher models, each of which do well in a specific domain.
- For each domain, the deep generic model is fine-tuned exclusively on the in-domain data to obtain the domain-specific teacher model.
ii) In-domain distillation:
- The goal of this step is to reduce the complexity of the original training data.
- For each domain, the domain-specific teacher model is used to translate the corresponding in-domain training and development data.
iii) Train a final multi-domain student model:
- The student model is shallower than the teacher models and is trained from scratch using both the training data (Ditr ) and the distilled training data (Didist(tr)) from all the domains.
Experiments and Results
Datasets:
The proposed approach is evaluated on two different translation tasks - German (DE)→English (EN) and English (EN)→French (FR) across multiple domains. The data statistics can be found in the table shown below:
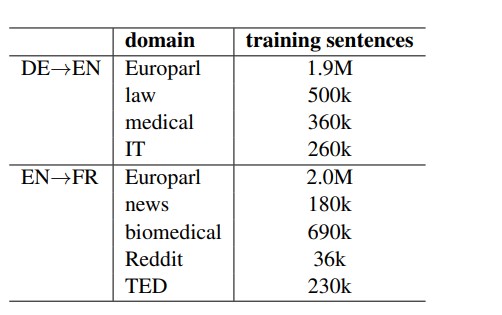
Table 1: Datasets used for the experiments
The authors carry out experiments with both unbalanced (keeping the original domain distribution) and balanced (upsampling) distribution of data across the multiple domains.
Experimental Setup:
The authors make use of transformer-base (Vaswani et al., 2017) implementation in Sockeye (Hieber et al., 2017) to train all the baseline, teacher and student models. For teacher models, they make use of 12 encoder and 12 decoder layers; for student and baseline models, they use 6 encoder and 6 decoder layer shallow architecture.
The Multi-domain baselines
i) multi-un: Model trained on the concatenated data from all the domains.
ii) multi-up: Model trained on the concatenated upsampled data from all the domains.
iii) fine-tune: This model is obtained by fine-tuning the multi-un model with the upsampled data from all domains.
iv) multi-tgt-tok: This model is trained using the same data as the multi-un model but by prepending a domain token to the target-side sentences.
Deep teacher models
Oracle of domain-specific teacher models trained by fine-tuning the deep generic model (trained on the concatenation of all data) exclusively on the in-domain data. This is to compare the proposed MDKD - shallow student model with the deep teacher models.
MDKD Models
i) MDKD-un: Shallow student model trained on the concatenation of original (Ditr ) and distilled version (Didist(tr)) of domain-specific corpora from all domains without changing the domain distribution.
ii) MDKD-up: Shallow student model trained on the upsampled Ditr and Didist(tr) data from all domains so that each domain has the same amount of training data.
Evaluation:
The authors make use of SacreBLEU (Post, 2018) to evaluate the performance of the trained models. They also conduct statistical significance tests using bootstrap resampling (Koehn, 2004).
Results & Findings:
German -> English
- Based on the automatic evaluation results, both MDKD models improve over all the baseline models by an average of 1 BLEU point.
- The MDKD models show improvements on the low-resource domains (law, medical and IT) and the MDKD-unbalanced model shows no significant degradation on any of the domains.
- The oracle model, which builds separate deep teachers for each domain, is the best performing method overall but the MDKD models (shallow architectures) do well in bridging the gap between the baseline models and the oracle across all the domains.
English -> French
- Surprisingly, the oracle model performs worse than the MDKD and the baseline models across all the domains.
- The authors hypothesize that the drop in quality of the oracle models could be due to the poor-quality domain labels. To validate the hypothesis, they compute the domain classification accuracy on the training and test sets and show that there are train/test mismatches in some domains.
- Despite using the distillation from the deep domain expert models that perform worse than the baseline models, the MDKD models don't show a degradation in quality.
In summary
Currey et al. (2020) propose Multi-Domain Knowledge Distillation (MDKD), a new method for multi-domain adaptation that uses multi-domain expert models to train a single shallow student model. This method is architecture independent and doesn’t increase the inference overhead. Based on the evaluation results, it can be seen that when the domains are well-defined, MDKD does a good job in improving the quality across domains and bridges the gap between the baselines and the deep expert models. In a noisy setting where domains are not clearly separable, the MDKD models show no degradation in performance.

Author
Akshai Ramesh
Machine Translation Scientist