
Introduction
While neural machine translation has made great strides over the years, one consistent struggle has been correctly disambiguating the different meanings a word can have. This is particularly difficult when some meanings or “senses” of a word are much rarer than others. Unless provided with enough examples of all contexts of a word, a neural machine translation model can be inclined to translate a word like “mole” the same, no matter if the mole is being removed by a doctor or by pest control. A disambiguation error like this where only one word is incorrect can render a translation incompressible.
In today’s blog we discuss a framework proposed by Hangya et al., 2021 that contextually mines back-translations of multi-sense words to increase frequency of rare sense words in training data and improve their translation.
Resources Used
Hangya et al., 2021 rely on three main resources for their framework:
- BabelNet, a multilingual resource with words labeled not only by the senses of meaning they have, but also potential translations of said senses
- the MuCoW datasets (Raganato et al., 2019), which were designed specifically for word sense disambiguation and provide parallel training corpora and a test set
- A random sample of 2 million German Wikipedia sentences to mine from
Hangya et al. work with English to German translation, although all of these resources are available in multiple languages. The authors particularly emphasize that this framework can be language and resource flexible as it doesn’t require any specific datasets or models. They choose XLM-R large for cross-lingual contextual word representations (CCWRs) after it consistently outperformed mBERT in their experiments, but any pre-trained multilingual model and monolingual corpus could recreate this process.
Framework Design
The authors first collect all the nouns used in the MuCoW test set and filter out any that only have one general sense registered on BabelNet, ending up with 3,732 multi-sense nouns. To find German sentences that use the target word with the same sense as in the test corpus, the authors use XLM-R large (Conneau et al., 2020) to create cross-lingual contextual word representations (CCWRs) of the multi-sense word in its English sentence, and measure cosine similarity with each word in each sentence in the German Wikipedia data. The top 5 scoring contextualized words and their sentences are then mined. To create parallel data, they mark out the collected multi-sense German word, back translate the sentence, and then replace the marker with the original English word, the intended multi-sense English word is present in the source sentences.
With such, they have created a synthetic parallel corpus of multi-sense word examples.
Evaluation
In order to directly test cases where there originally was few or no training data for a given sense of a word, the authors split the MuCoW test set into “rare” and “unseen” subsets. For the unseen set, they remove all training data of the least common sense of each word. For the rare set, they remove a random 10% of each word’s training data (named “sample-10”), effectively lowering the frequency while maintaining the sense distribution.
The authors train base transformer NMT models on each of these parallel data sets to function as their baselines. They then fine-tune those baselines with a concatenation of the original training data and their new synthetic data to create their CMBT model. As baseline to measure the importance of context for their cross-lingual mining, they also evaluate a fine-tuned model on data collected with context-independent bilingual word embeddings (BWE).
In this paper F1 is calculated where precision is the total correct senses over the sum of the correct and incorrect sense translations, and recall is the ratio of total correct senses to all multi-sense words (a sense is neither correct nor incorrect if none of the possible translations for the sense are found).
Example
As anecdotal representations of how models fine-tuned on the synthetic parallel data differ compared to the baseline, the authors provide examples such as below:
 In the above, both BWE and CMBT show improvement on the baseline by correctly translating “arms” as appendages instead of “weapons.” However, only the context-aware method, CMBT, correctly translated the source word “bank” as a river bank.
In the above, both BWE and CMBT show improvement on the baseline by correctly translating “arms” as appendages instead of “weapons.” However, only the context-aware method, CMBT, correctly translated the source word “bank” as a river bank.
Results
To systematically analyze the effect of the mined data on rare senses, the authors break results into two tables: analyzing translations of just the rarest sense of a word (which can be “unseen” in the original training data or just uncommon) and analyzing performance on all senses of each word. E.g., for the multi-sense word “bank”, the first table evaluates translations of the side of a river, and the second evaluates river “banks” and financial “banks.” Below, “bin” refers to the frequency of the tested sense in the training data relative to the other senses of the word, and “#” is the number of test cases in each bin by the thousands.
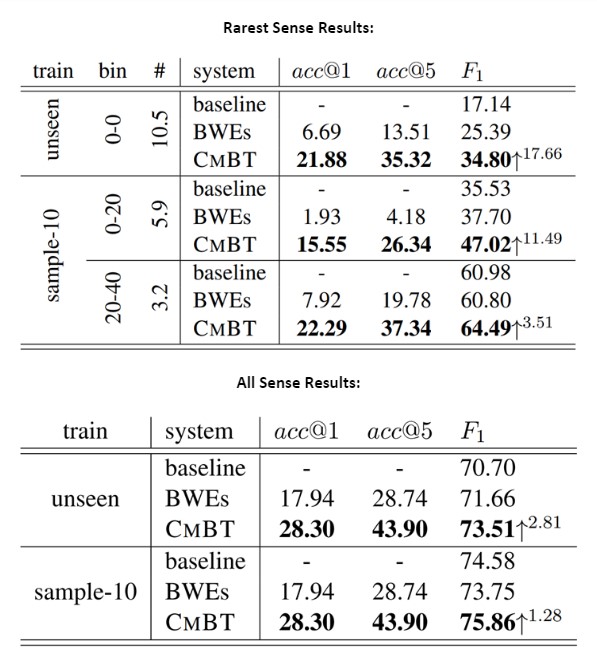 For the rare sense translations, the models fine-tuned with the CMBT data consistently outperform the baselines for F1 and accuracy in having the correct sense represented in the top n mined sentences. The gains on the baseline lessen, however, as the frequency of the sense in the original training data increases. This is also evident in the all-sense results, where CMBT still has the highest accuracy and F1 though it only marginally improves on the baseline. This is unsurprising considering higher frequency senses would already be translated well, but is encouraging that adding the mined data doesn’t lower quality for well-represented senses.
For the rare sense translations, the models fine-tuned with the CMBT data consistently outperform the baselines for F1 and accuracy in having the correct sense represented in the top n mined sentences. The gains on the baseline lessen, however, as the frequency of the sense in the original training data increases. This is also evident in the all-sense results, where CMBT still has the highest accuracy and F1 though it only marginally improves on the baseline. This is unsurprising considering higher frequency senses would already be translated well, but is encouraging that adding the mined data doesn’t lower quality for well-represented senses.
The authors also experimented with the sentence selection by limiting the mined German sentences to the translations BabelNet provides (CMBT+) and by collecting all possible translations instead of the top 5 (ALL+). The F1 arrows indicate the relative change to the aforementioned scores above.
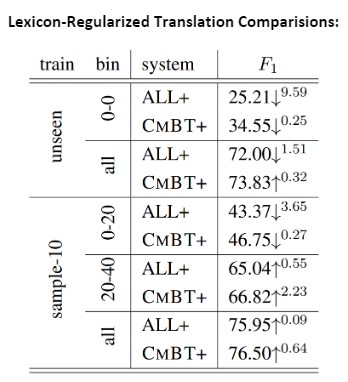 Both methods lower performance in rarer settings while making only small F1 gains in the higher frequency settings. This suggests that not only would future experiments have quality results without needing the translations provided by BabelNet, but also that the embedding similarity ranking method particularly improves the rare sense translations, as intended.
Both methods lower performance in rarer settings while making only small F1 gains in the higher frequency settings. This suggests that not only would future experiments have quality results without needing the translations provided by BabelNet, but also that the embedding similarity ranking method particularly improves the rare sense translations, as intended.
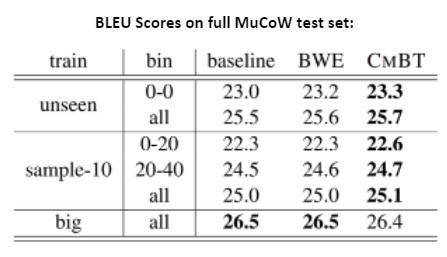 At a sentence-level evaluation, the BLEU scores show very mild improvements on the baselines, except for MuCoW’s big test set. The authors note that this is to be expected since the goal is to change only specific words in each sentence, which BLEU is not as sensitive to.
At a sentence-level evaluation, the BLEU scores show very mild improvements on the baselines, except for MuCoW’s big test set. The authors note that this is to be expected since the goal is to change only specific words in each sentence, which BLEU is not as sensitive to.
In summary
Hangya et al, 2021 propose a text mining and back translation framework, CMBT, to improve translations of rare senses of words. The evaluations show this framework provides a non-invasive increase in accuracy and F1 scores for rare senses, while maintaining the translations of the common senses of words and the BLEU score quality of full sentences. Since this method is independent of any specific source, it can potentially be applied to any language with enough data to train a NMT model and have a multilingual model for contextualized word embeddings.

Author
Katrina Olsen
Research Engineer