
Introduction
Neural Machine Translation (NMT) can achieve high quality when trained using deep architectures on large amounts of relevant data. At the same time, it has been demonstrated that NMT models are more sensitive to noisy parallel training data than the phrase-based statistical models Khayrallah and Koehn (2018), Belinkov and Bisk (2017). This results in the need for methods to filter harmful sentence pairs from the large training corpus. In today’s blog post, we will take a look at the work of Zhang et al. (2020) who propose a novel approach for parallel corpus filtering.
The Approach
The authors propose the use of 3 filters: language detection, acceptability and domain. For every pair of candidate source/target sentences from the noisy parallel corpus, the three filters produce separate partial scores between 0 and 1 and the final score is computed as the product of the partial scores from the three filters.
Language Detection Filter:
- They adopt the fastText Joulin et al. (2016) language identification toolkit to discard the sentence pairs with undesired languages.
- For a given sentence, the toolkit generates a list of language candidates along with the confidence level scores for each language.
- The authors assign a score of 1 to each sentence pair from the parallel corpus if the candidate language with the highest score for both the source and target sentence is as desired, otherwise they assign a score of 0.
- Using the language filter, they filter out almost 70% of the German-English Paracrawl corpus and 27% of the Chinese-Japanese web crawled parallel corpus.
Acceptability Filter:
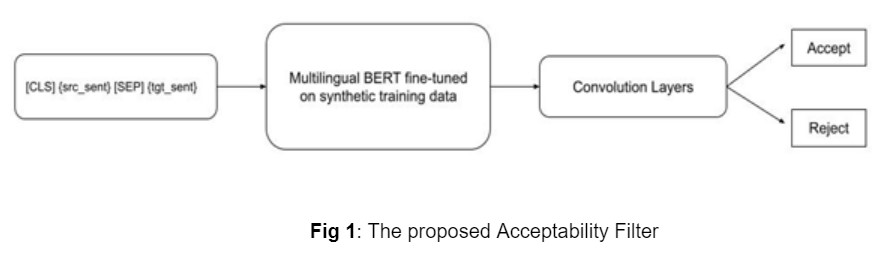 Generating the Synthetic training set: First, they generate a synthetic training set with a balanced amount of both positive and negative samples.
Generating the Synthetic training set: First, they generate a synthetic training set with a balanced amount of both positive and negative samples.
- For the positive samples (mutual translations): If clean parallel data is available, they select a subset from it (supervised acceptability), else they sub-select sentence pairs with high confidence scores marked by the Hunalign sentence alignment tool (unsupervised acceptability).
- Negative samples are generated by adding noise to the positive samples in one of the following ways: randomly select a target sentence from its adjacent sentences within a window size of k=2, truncate 30-70% of the source/target sentence, swap 30-70% of the word order in source or target sentence.
- Binary Classification task: The generated synthetic parallel corpus is used to fine-tune the multilingual BERT model. As shown in Fig.1, the noisy parallel corpus sentence pairs are passed as an input to the fine-tuned model using the next sentence-prediction objective Devlin et al. (2019) and the BERT output is fed into a Convolutional Neural Network (CNN) with a softmax activation function in the final feed-forward network, which gives the label probabilities for each sentence pair input.
- As the name suggests, this filter is used to select the in-domain sentence-pairs from the noisy parallel corpus. For this, they adopt the cross-entropy difference based scoring method proposed by Moore and Lewis (2010) and Junczys-Dowmunt (2018).
- The score is computed as a perplexity ratio between 2 language models LI and LN where LI is the language model trained on in-domain monolingual corpus I and LN is the language model trained on non-domain data N. This gives the measure of how the target sentence t is related to in-domain data I and less related to out-of-domain data N.
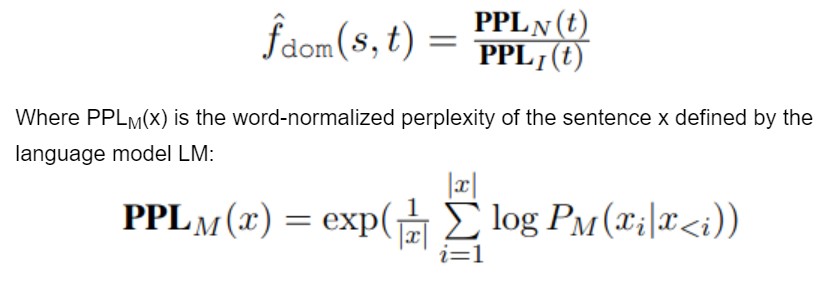
- Instead of using the news domain text Junczys-Dowmunt (2018) for an in-domain language model, the authors make use of GPT Radford et al. (2019) which is trained on a wide range of data from Wikipedia, Reddit, news, websites etc.
- As in Junczys-Dowmunt (2018), they use the clip and cut-off operation for post-processing the domain filter score.
Experiments and Results
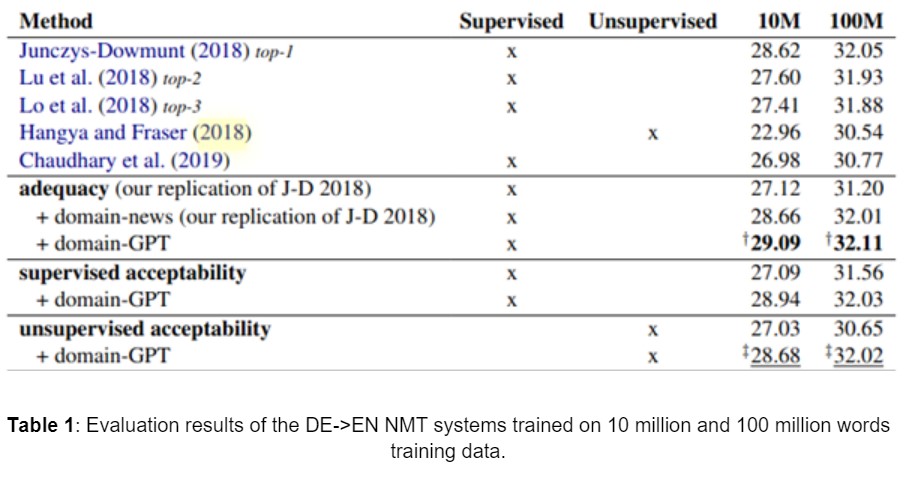
- This task involves filtering sentence pairs of 2 sizes: 10 million words and 100 million words, counted on the English side from the given web crawled DE-EN parallel corpus of 104 million sentence pairs. Use the filtered data to train neural machine translation systems.
- The authors report the results in comparison with the top 3 performers from the shared task (top-{1,3} in Table 1) along with 2 other works: Chaudhary et al. (2019) and Hangya and Fraser (2018) that are similar to their work.
- The authors replicate the dual conditional cross-entropy filtering method proposed in Junczys-Dowmunt (2018). This method is referred to as “adequacy” in Table 1. They conduct experiments with both supervised acceptability and unsupervised acceptability.
- The results are reported in terms of BLEU score Papineni et al. (2002) and can be found in the table below:
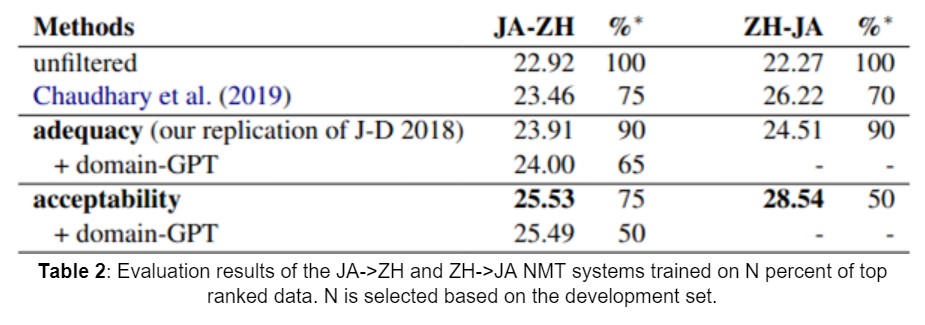
- They release a large noisy web-crawled Japanese-Chinese parallel corpus for research purposes. This corpus consists of 20.9 million sentence pairs and the task is to build the best possible NMT system for JA->ZH and ZH->JA without any limits on the amount of filtered data.
- The “unfiltered” method in Table 2 refers to the data generation using the Hunalign tool without performing any actual filtering. They also compare the results with LASER by Chaudhary et al. (2019), the top performing filtering system in WMT 2019 Parallel Corpus Filtering shared task.
- The results are reported in terms of BLEU score and can be found in the table shown below:
 In summary
In summary
Tags:
Language Weaver
Author
Akshai Ramesh
Machine Translation Scientist