
Introduction
Taking into account context information in neural MT is an active area of research, with applications in document-level translation, domain adaptation and multilingual neural MT. Today we take a look at a method which combines predictions from a neural MT model and from a nearest neighbour classifier, retrieved from similar contexts in a datastore of cached examples. This approach, called “Nearest Neighbor Machine Translation”, was proposed by Khandelwal et al. (2020).
Description of the Method
In nearest neighbour MT, the translation is generated word-by-word. For each word, the most similar contexts are found in the datastore, and a distribution over the corresponding target tokens is computed. This distribution is then interpolated with the output distribution from a previously trained neural MT model. This process is described in the following figure. 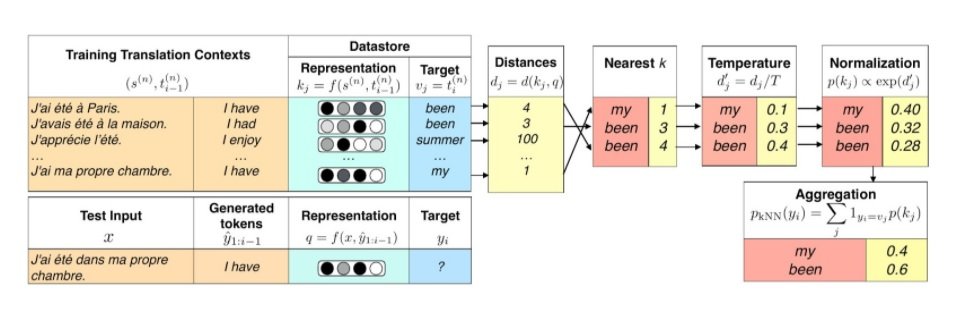
The translation contexts are taken from parallel training data and are composed, for each target word of each example, of the complete source side and the prefix before this target word (top orange columns in the figure). The datastore is constructed offline and consists of a set of key-value pairs. The key is an intermediate decoder representation of the entire translation context (top green column) and the value is the training target token coming after the context target prefix (top blue column).
During generation, the query representation (bottom green column), conditioned on the test input as well as previously generated tokens, is used to retrieve the k nearest neighbours from the datastore, along with the corresponding target tokens. The distance from the query is used to compute a distribution over the retrieved targets after applying a softmax temperature (yellow and red columns). This distribution is the final kNN distribution.
The authors argue that a pure kNN approach is effective, but the results are improved by interpolating this kNN distribution with the neural MT model distribution. This interpolation is indeed more robust in cases without relevant cached examples. The complete translation is generated using beam search.
Results
The nearest neighbour MT approach is evaluated under three settings: single language-pair translation, multilingual MT and domain adaptation. For the single language pair translation, it is performed on the German-English news translation task, on the test set of the 2019 WMT shared tasks, with the BLEU score. The neural MT engine used in the interpolation, and baseline of the evaluation, is the winner of the 2019 WMT German-English news shared task. The multilingual system is trained on the CCMatrix data. In the domain adaptation setting, a multi-domain dataset including 5 domains is used: Medical, Law, IT, Korean and Subtitles.
In single language-pair translation, the datastore was constructed from the original training set (770M tokens of WMT 2019 training data). With nearest neighbour MT, the BLEU score was improved by 1.5 points.
The proposed approach is particularly interesting when the datastore differs from the original set. In this case it allows us to adapt a multilingual engine to a specific language or a generic bilingual engine to a specific domain, without retraining. In the multilingual MT setting, using a datastore in a specific language improves the multilingual neural MT engine by 1.4 BLEU on average, across 17 language pairs. In the domain adaptation setting, retrieving nearest neighbours yields an improvement of 2.5 BLEU on average (over the 5 domains) over the neural MT engine trained on all the domains, and 9 BLEU on average over the neural MT engine trained on generic out-of-domain data (WMT’19 data).
Unfortunately, these results come at a very high computational cost. During inference, retrieving 64 keys from a datastore containing billions of items results indeed in a generation speed that is two orders of magnitude slower than the base neural MT system.
In summary
This paper proposes an approach to interpolate the neural MT model probability distribution with a distribution built from nearest neighbours of the target words retrieved from a datastore of cached contexts. This approach improves the results in three settings, without need for retraining: single language pair MT, multilingual MT and domain adaptation. It is very interesting because it gives more evidence of the impact of providing context information online in neural MT. However, the computational cost of this particular method makes it difficult to use in real-world settings.
Author
Dr. Patrik Lambert
Senior Machine Translation Scientist