
Introduction
In the training of neural machine translation (NMT) systems, determining how to take advantage of monolingual data and improve the performance of the resulting trained models is a challenge. In this post, we review an approach proposed by Zhou and Keung (2020), under the framework of non-autoregressive (NAR) NMT. The results confirm that NAR models achieve better or comparable performance compared to state-of-the-art non-iterative NAR models.
NAR-MT with Monolingual Data
Zhou and Keung (2020) see the “NAR model as a function approximator of an existing AR (autoregressive) model”. The input of the approach is an AR model and source sentences. Firstly, the AR (teacher) model is used to obtain the output. Then the output is paired with source sentences and used to train the NAR model. Under the framework, it is easy to incorporate monolingual data in the training. Zhou and Keung (2020) used the AR model to translate more data from the source language, which makes the resulting parallel corpus more generalised for the training of the NAR model.
Experiments and Results
Zhou and Keung (2020) used WMT16 English--Romanian (En-Ro) and WMT14 English--German (En-De) datasets for experiments, which are approximately 610k and 4.5M sentence pairs, respectively. For monolingual data used in the experiments of En-Ro models, the “Romanian portion of the News Crawl 2015 corpus and the English portion of the Europarl v7/v8 corpus” are used. Table 1 shows the gain in BLEU using different amounts of monolingual data to prepare the parallel corpus for the training of NAR models. The “gold” in the figure indicates that true target lengths are used in the experiments, rather than predictions. The experiments showed consistent results that the more we incorporate monolingua data for AR models to produce sentence pairs for NAR training, the better the performance achieved on the resulting models. The state-of-the-art results for En-to-Ro and Ro-to-En MT performance are 32.20 and 32.84 in terms of BLEU, respectively. The proposed method achieved 34.50 and 34.01 using an AR Transformer with beam setting as 4. Similar results exhibited in the En-to-De and De-to-En experiments. 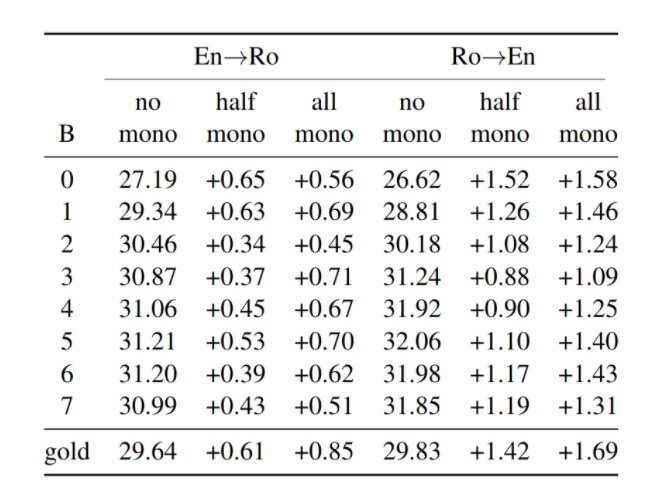 Table 1. BLEU scores of NAR models trained on English--Romanian language pairs in both directions. B refers to the number of length candidates determined, while gold refers to using true target length. Excerpted from Zhou and Keung (2020).
Table 1. BLEU scores of NAR models trained on English--Romanian language pairs in both directions. B refers to the number of length candidates determined, while gold refers to using true target length. Excerpted from Zhou and Keung (2020).