
Introduction
The lack of parallel training data has always been a big challenge when building neural machine translation (NMT) systems. Most approaches address the low-resource issue in NMT by exploiting more parallel or comparable corpora. Recently, several studies show that instead of adding more data, optimising NMT systems could also be helpful to improve translation quality for low-resource language cases.
In this post, we will review a paper by Araabi and Monz (2020) that explores to what extent hyper-parameter optimisation can help to improve low-resource NMT. Sennrich and Zhang (2019) investigated the best practices for low-resource recurrent NMT models. This paper focuses on the Transformer models, the most commonly used approach by both academic and industry communities nowadays.
Hyper-Parameter Exploration
Many studies (Raffel et al., 2019; Wang et al., 2019) show that increasing the number of model parameters improves performance of Transformer models with enough training data, but are those findings also the best practices for low-resource scenarios?- Byte-Pair-Encoding (BPE) segmentation
- Architecture tuning
Biljon et al. (2020) showed that using fewer Transformer layers improves the quality of low-resource cases. In this paper, they expand the experiments to explore the effects of using a narrow and shallow Transformer by reducing:
- the number of layers in both the encoder and decoder,
- the number of attention heads,
- feed-forward layer dimension, and
- embedding dimensions.
- Regularisation
They investigate the impact of regularisation by applying dropouts to various Transformer components:
- employ attention dropout after the softmax for self-attention and also activation dropout inside the feed-forward sub-layers,
- drop entire layers using layer dropout (Fan et al., 2020),
- drop words in the embedding matrix using discrete word dropout (Gal and Ghahramani, 2016).
Experiments
Transformer-base and Transformer-big are used as baselines, with the default parameters and optimiser settings described in Vaswani et al. (2017). To compare with Sennrich and Zhang (2019), the first engines are trained on the same TED data from the IWSLT 2014 German-English (De-En) shared translation task (Cettolo et al., 2014). The training and validation sets are 165,667 and 1,938 sentence pairs respectively. The test set is the concatenation of the IWLST 2014 dev sets (tst2010–2012, dev2010, dev2012), which consists of 6,750 sentence pairs. Besides, they also evaluate the obtained optimised settings on Belarusian (Be), Galician (Gl), and Slovak (Sk) TED talk test sets (Qi et al., 2018) and Slovenian (Sl) from IWSLT2014 (Cettolo et al., 2012) with training sets ranging from 4.5k to 55k sentence pairs. Grid search is applied to explore the hyper-parameters for computational effectiveness.Results and observations
Table 1 shows the optimal settings achieved on the development data with different dataset sizes and Table 2 shows the experiment results of Transformer-base/optimised on different language pair datasets .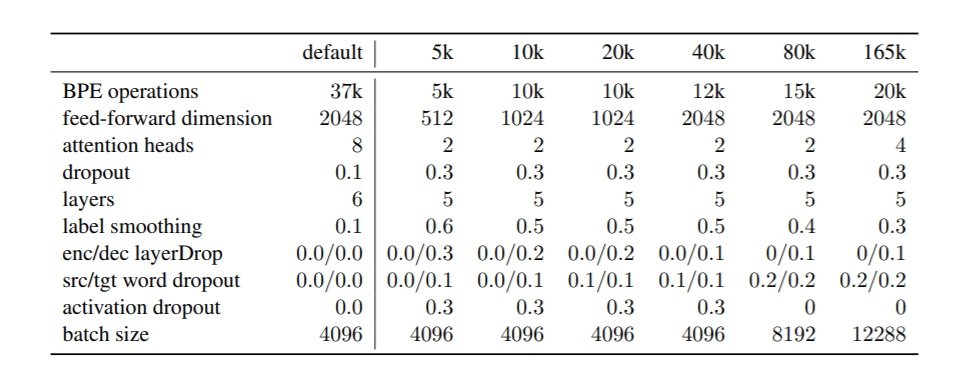
Table 1: Default parameters for Transformer-base and the achieved optimal settings for different dataset sizes based on the De→En development data.
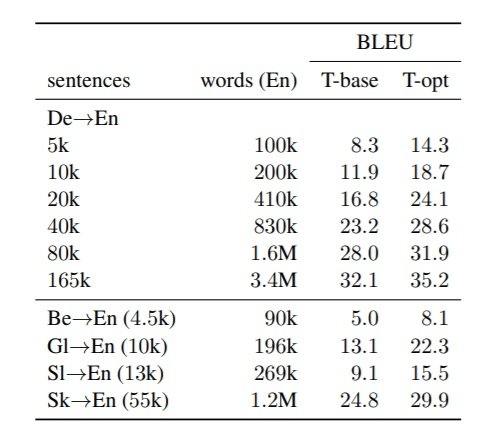
Table 2: Results for Transformer-base/optimised.
According to the experiment results, the observations are:
- Compared to the big improvement achieved with the RNN model by reducing BPE merge operations (Sennrich and Zhang, 2019), the results from this paper demonstrate that the same reduction in merge operations has far less impact on the Transformer model and reducing the embedding dimension size is not effective.
- Reducing Transformer depth and width, including number of attention heads, feed-forward dimension, and number of layers along with properly increasing the rate of different regularisation techniques is highly effective (+6 BLEU) for low-resource cases.
- Increasing dropout rate, adding layer dropout to decoder, and adding word dropout to the target side, can all be helpful to improve low-resource Transformer quality, but the effect becomes less obvious with the increase in data size.
- Higher degree of label smoothing and higher decoder layer dropout rates are beneficial for smaller data sizes and less effective for larger sizes.
- Transformer requires large batch sizes even with very small datasets.
- Compared to the default Transformer learning rate scheduler, no significant improvement is observed with different learning rates and warm-up steps.
- Applying attention dropout does not result in improvements under low-resource conditions.
- The results are promising on the reverse direction EN-DE with the same IWSLT 2014 data and same optimal settings.
In summary
This paper investigates the impact of different parameter settings on low-resource Transformer models. Most of the findings are in line with the work on RNN models by Sennrich and Zhang (2019), except some effective options for RNN models such as reducing the number of BPE merge operations and using small batch sizes seem unhelpful for Transformer models. According to the experiment, a proper optimisation indeed improves significantly the baseline performance and the optimal settings are closely related to the data size.
Author
Dr. Jingyi Han
Machine Translation Scientist