
Introduction
Although deep neural models produce state-of-the-art results in many translation tasks, they are found to underperform phrase-based statistical machine translation in resource poor conditions. The majority of research on low-resource neural machine translation (NMT) focuses on the exploitation of monolingual or parallel data involving other language pairs. There is notably less attention into the research of low-resource NMT without the use of auxiliary data.
In today’s blog post, we will look at the work of Sennrich and Zhang, 2019 that comes from the University of Edinburgh. This paper investigates the best practices for low-resource recurrent NMT models and shows that more efficient use of small amounts of parallel training data can result in strong improvements across different data settings without relying on auxiliary resources.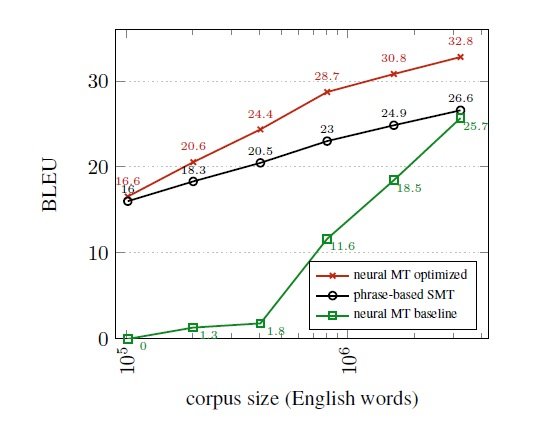 Fig 1: German→English learning curve, showing BLEU as a function of the amount of parallel training data, for PBSMT and NMT.
Fig 1: German→English learning curve, showing BLEU as a function of the amount of parallel training data, for PBSMT and NMT.
In Koehn and Knowles (2017), they show that it takes in the order of millions of sentences in the training data for an NMT system to outperform the PBSMT system. Their NMT systems are trained with the same hyperparameter configuration as used for the high-resource scenarios and the hyperparameters are not tuned for the low resource conditions. Sennrich and Zhang (2019) re-visit this scenario and show that following a set of best practices and tuning the hyperparameters to the low-resource setting, the optimised NMT system can outperform the statistical models with as little training data as 105 words.
Methods to optimise NMT in low-resource setting
- Mainstream Improvements: This includes common architectural changes like adding dropout, tied embeddings, layer-normalisation, label smoothing, learning-rate, and bidirectional RNN.
- Reduce BPE Vocabulary size: In a low-resource setting, a large BPE vocabulary will lead to low-frequency subwords being represented as atomic units, limiting good high-dimensional representation. So they reduce the BPE vocabulary based on a subword frequency threshold as suggested in Sennrich et al. (2017a). (Here 14k to 2k subword units)
- Hyperparameter Exploration: Reducing the batch-size, number of layers and introducing aggressive dropout (word).
Experiments
In this paper, the authors present their work on 2 language pairs - German→English (full training data of 159k parallel segments with the smallest subset of 5k parallel segments) and Korean→English (training data of 90k parallel segments). The experimentation is carried out on different smaller subsets of the German-English training data starting from 5k segments and all the way to whole training data of 160k segments.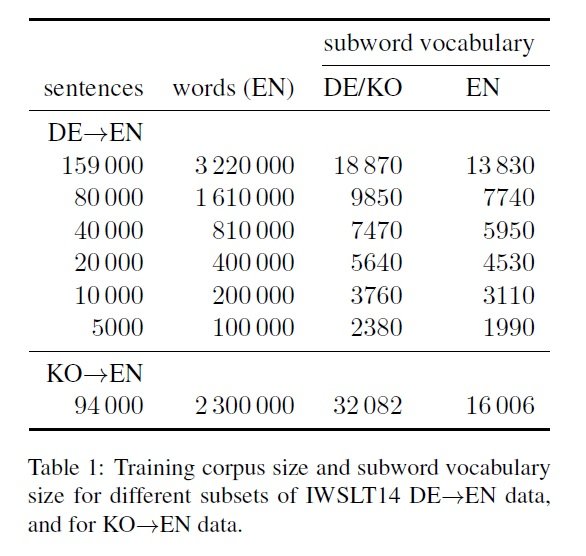 Moses (Koehn et al., 2007) is used to train a PBSMT system. The NMT systems are trained with Nematus (Sennrich et al., 2017b). For the purpose of comparison, the hyperparameters from Koehn and Knowles (2017) are used to train the baseline NMT system. The methods discussed in the previous section are subsequently added to the baseline system with the objective to optimise the NMT system and outperform the PBSMT system without using any auxiliary data.
Moses (Koehn et al., 2007) is used to train a PBSMT system. The NMT systems are trained with Nematus (Sennrich et al., 2017b). For the purpose of comparison, the hyperparameters from Koehn and Knowles (2017) are used to train the baseline NMT system. The methods discussed in the previous section are subsequently added to the baseline system with the objective to optimise the NMT system and outperform the PBSMT system without using any auxiliary data.
Evaluation Results & Observations
Table 2 shows the effect of adding different methods to the baseline NMT system, on the ultra-low data condition (100k words of training data) and the full IWSLT 14 training corpus (3.2M words). The mainstream improvement method leads to a 6-7 increase in BLEU points across both corpus-sizes.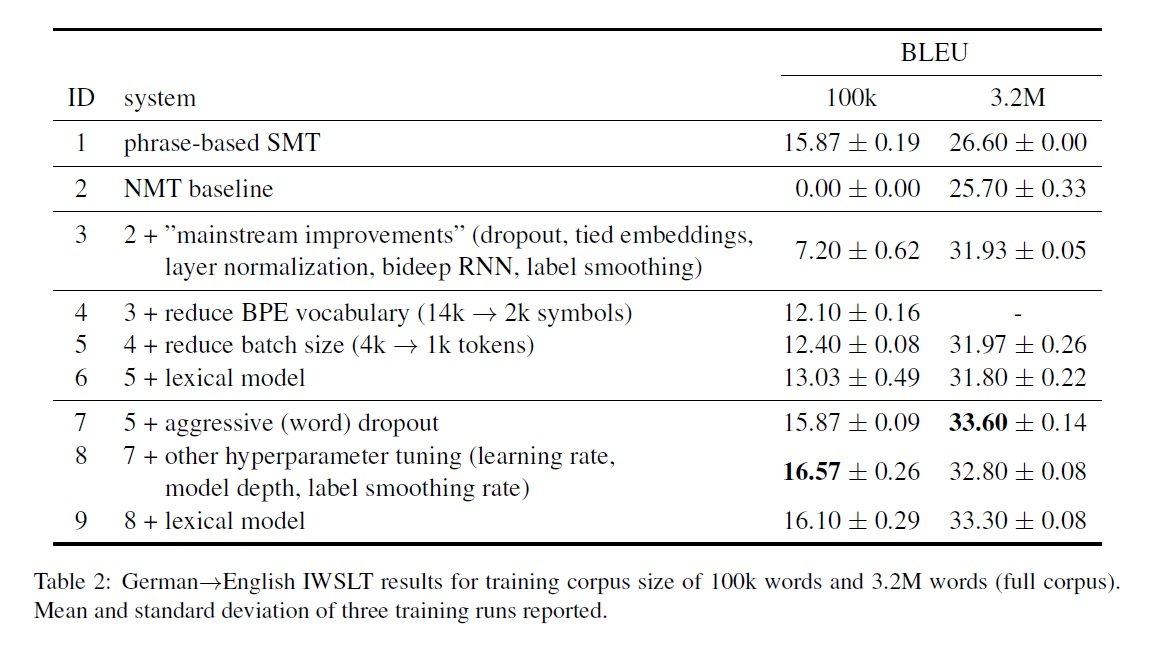 In the ultra-low data condition, shrinking the BPE vocabulary leads to a +4.9 BLEU. The use of smaller mini-batches helps to achieve a +0.3 BLEU. Adding aggressive word dropout seems to be very effective and yields a +3.5 BLEU improvement. Additionally, using fewer layers and other hyperparameters tuning (learning rate, label smoothing rate, etc.) results in the optimised NMT system outperforming the PBSMT system. Also, in the Korean→English language direction, the optimised NMT system shows strong improvements and outperforms the PBSMT system across all data settings.
In the ultra-low data condition, shrinking the BPE vocabulary leads to a +4.9 BLEU. The use of smaller mini-batches helps to achieve a +0.3 BLEU. Adding aggressive word dropout seems to be very effective and yields a +3.5 BLEU improvement. Additionally, using fewer layers and other hyperparameters tuning (learning rate, label smoothing rate, etc.) results in the optimised NMT system outperforming the PBSMT system. Also, in the Korean→English language direction, the optimised NMT system shows strong improvements and outperforms the PBSMT system across all data settings.
Other Observations
- NMT baseline (0 BLEU) unable to learn from 5,000 parallel segments, whereas tuning the hyperparameters following the best practices leads to the optimised NMT resulting in 16.6 BLEU.
- Reducing the BPE vocabulary size for German→English full training data doesn’t result in significant improvement.
- Aggressive dropout and other hyperparameters tuning has a stronger impact than the lexical model and adding a lexical model on top of the optimised configuration doesn’t improve the performance.
In Summary
Most research on low-resource NMT focuses on using auxiliary data to improve the system performance but Sennrich and Zhang (2019) show that low-resource NMT is very sensitive to hyperparameters and proper tuning of these hyperparameters can lead to stronger baselines. They also carry out best practices for low-resource recurrent NMT models and also show that an optimised NMT system can show strong improvements, and outperform the PBSMT system across all data settings.

Author
Akshai Ramesh
Machine Translation Scientist