

Look It Up: Bilingual and Monolingual Dictionaries Improve Neural Machine Translation
Introduction
How to integrate external knowledge into Neural Machine Translation (NMT) properly has always been an attractive topic for both industrial practice and academic research. It can be very useful for domain adaptation and human references integration. There have been some approaches that try to incorporate bilingual dictionaries into NMT: Qi et al. (2018) and Hamalainen and Alnajjar (2019) extended the model to generate translations from automatically extracted dictionaries; Post and Vilar (2018) tried to constrain the decoder to produce translation candidates from the dictionary; and Michon et al. (2020) applied placeholders complemented with morphosyntactic annotation that can efficiently produce correct word forms in most cases. In this post, we take a look at a paper by Zhong and Chiang (2020) that proposes a special position encodings (PE) to include the external dictionary definitions for unknown source entries (UNKs).
Special position encodings for external knowledge integration
The main strategy applied in this paper is based on the Transformer, but besides the normal PE for each source entry, they also try to attach the translation definitions ( limited to the first 50 tokens ) for each source unknown word/subword by using a special position encoding scheme that is different from the global PE.
More specifically, N (N = token number of the definition for each UNK) new token embeddings will be added to the end of each source sentence, each new token is represented as:
E[d] = WE[f]+PE[p]+WE[d]+DPE[q]
in the formula above, WE[f] is the word embedding (WE) of word f and PE[p] is the usual sinusoidal PE of word f at position p. Then suppose that this word f at position p is an UNK and has an external translation definition, then the word d at position q from the definition of the UNK is attached by adding its own WE WE[d] and PE DPE[q]. Here is an example of attaching the definition “the Dead Sea” to the UNK token at position 4: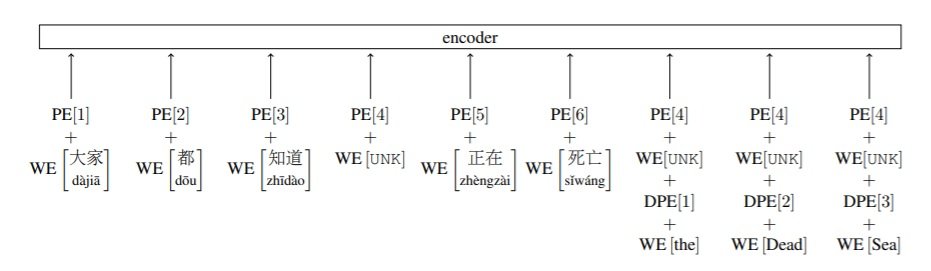
Experiments
The experiments were conducted with a Transformer network on two language pairs: Chinese-English and German-English. The authors compared this dictionary attachment strategy (Attach) against two other models: a standard Transformer without any dictionary entries (Baseline) and another standard Transformer with bilingual dictionary entries included as parallel sentences in the training data (Append).
The evaluation was done on both word-level and subword-level. For the subword level, all words are split into multiple subwords, but the dictionary definitions are only matched to words. So to overcome this issue, they fused all the subword tokens from an UNK word into a single token, which often makes the combination fall out of the vocabulary and is therefore changed back to UNK again. Then the definition is attached to this reunited single token.
In addition to bilingual dictionaries, they also tried to incorporate monolingual source dictionaries to improve the performance since this method does not make any assumptions about the form of definitions. In this case, the dictionary entries are, of course, written in the source language.
Result and discussion
According to the results, the Append method is not helpful, and it performs even worse than the Baseline in most of the cases. By contrast, the proposed Attach method with bilingual dictionary entries improves the Baseline translation quality significantly on both word-level and subword-level by up to 3.1 BLEU. Compared to using a bilingual dictionary, a monolingual source dictionary has less impact on the translation performance with a slight improvement of around 0.7 BLEU.
Although this Attach method can be used to properly integrate external knowledge to the Transformer network, the inefficiency is the most important limitation as it increases the length of the source sentences significantly, hence the training and decoding processes take 2-3 times longer. Besides, the improvement of this method depends on the quality and coverage of the dictionaries.
In summary
Zhong and Chiang (2020) provide a simple yet effective way to integrate external knowledge (both bilingual and monolingual dictionary entries) into a Transformer network by applying a special position encoding strategy. Different from other approaches that only take into account the target translation candidates, this method can integrate the whole dictionary definitions and the model is capable of selecting and adapting parts of the definition to the final translation. This strategy might also be useful for word sense disambiguation for NMT as well.Author
Dr. Jingyi Han
Machine Translation Scientist