
Introduction
While Neural Machine Translation is generally fluent, it occasionally can be deceptively so, either omitting or adding fragments. In today’s post we examine a method proposed to address this shortcoming and make the model more faithful to the source; Weng et al. (2020) propose a faithfulness-enhanced NMT model, called FENMT.
The Problem
They surmise that there are potentially 3 possible causes for this faithfulness problem in the encoder-decoder framework:
- Some parts of input are hard to encode and therefore not translated correctly.
- The decoder cannot retrieve the correct contextual representation from the encoder.
- In aiming for fluency, the language model encourages common words.
They then propose a novel training strategy to try and handle it.
Approach
The approach consists of collecting fragments that they deem ‘mistranslated’ and then deploying various tactics to try and train the model to translate them correctly.
Firstly, they collect the ‘mistranslated fragments’ in the following manner:
- Align source and target sentences in the training set, and generate a phrase table.
- At each training epoch sample a subset and translate it.
- Identify mistranslated fragments, whereby a mistranslated fragment is defined as a continuous segment from the reference which is not in the MT output but is in the extracted phrase table. This is the case for ‘litigation exhaustion’ in the example illustrated below.
- Use alignments to get the corresponding source words.
 Then, they deploy a multi-task learning paradigm to learn to correctly translate these fragments, with the following components aiming to address the postulated causes listed above (under ‘The Problem’):
Then, they deploy a multi-task learning paradigm to learn to correctly translate these fragments, with the following components aiming to address the postulated causes listed above (under ‘The Problem’):
- Masked language model (MLM) task (LM) to better infer the input words which were presumed not correctly translated: similar to BERT (Devlin et al. (2019)), but for a given input sentence x the mistranslated subsequence xM will have words replaced with <MASK> token. The aim is to improve the contextual representation of the input words.
- Word alignment task (LA) to improve the accuracy of the encoder-decoder cross-attention and hopefully capture correct contextual representations for each output word.
- Max-margin task (LC) based on contrastive learning, to mitigate the tendency to translate with frequent (yet possibly wrong) words. Instead of simply using cross-entropy, they integrate max-margin loss.
LF = LT + α · LM+ β · LA + γ · LC
Where α, β and γ are set to 0.3. The overview of the training strategy is depicted below, whereby the NMT engine translates sampled sentences at the end of the tth epoch, and the multi-task learning is deployed to further train the model. This continues in an iterative manner, as per diagram below.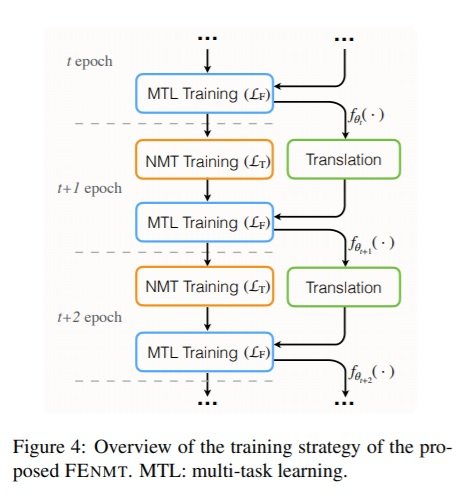
Experimental setup
The experiment encompasses 3 language pairs from the following datasets: WMT17 Chinese (ZH)-English (EN), WMT14 English (EN)-German (DE), WMT16 English (EN)-Romanian (RO) with 7.5M, 4.5M, and 0.6M sentence pairs respectively. Alignment is with fast_align, and the phrase tables extracted are limited to length 2-4, resulting in 6.7M, 3.4M and 0.2M phrases for above. They implement Transformer-Base and Transformer-Big as baselines, in addition to 3 other approaches: self-supervised learning to fine tune the model, minimum risk training (MRT), and Knowledge Distillation.Results
Automatic evaluation
In terms of automatic evaluation, the proposed FENMT model scores up to 1.03 BLEU points higher than the Tranformer-Base for the ZH-EN language pair. For DE-EN the results are slightly lower, with an increase of 0.88 BLEU points. EN-RO shows the highest increase at 1.2 BLEU points. Since this approach affects the training process alone, the inference efficiency is unaffected.Human evaluation
Given that BLEU cannot accurately evaluate translation quality, in particular the severity of any error, human evaluation is carried out to further assess the impact of FENMT. A professional translator is tasked with labelling 100 sampled sentences from the ZH-EN testset. Results are displayed in the table below, and indicate that the paradigm can reduce the amount of ‘Major’ errors significantly, and cut the ‘Critical’ ones by half. This has a direct impact on the users of MT output, and is therefore of great interest to us at Iconic. The human translator was also asked to rank the translations to further evaluate the quality. Again this indicates that FENMT seems to reduce the amount ranked as poor translations and increase those that are ranked as good and excellent.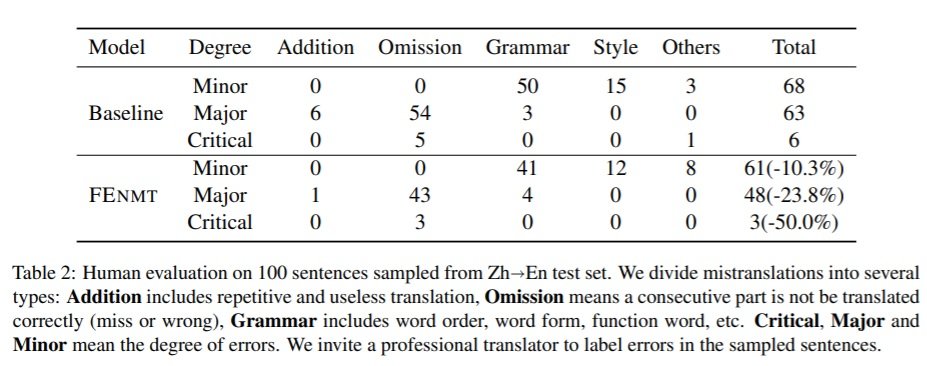 The ablation study investigates which of the three new objectives has the largest impact, and indicates that the MLM results in the biggest improvement. Together with either the word alignment or max margin objective, it can reach close to the results of all 3 combined.
The ablation study investigates which of the three new objectives has the largest impact, and indicates that the MLM results in the biggest improvement. Together with either the word alignment or max margin objective, it can reach close to the results of all 3 combined.
Conclusion
FENMT deploys a multi task approach in order to try and improve the faithfulness of mistranslated fragments within a segment. Both automatic and human evaluations suggest that they have succeeded in doing so.
Author
Dr. Karin Sim
Machine Translation Scientist