
Introduction
In recent years, Neural machine translation (NMT) based on the encoder-decoder architecture has significantly improved the quality of machine translation. Despite their remarkable performance, NMT models have a number of flaws (Koehn and Knowles, 2017), one of which is the issue of unbalanced outputs in translation. Current neural machine translation (NMT) approaches produce the target language sequence token-by-token from left to right that results in the prefixes being translated better than the suffixes in a segment (Liu et al., 2016).
In today’s blog post, we will look at the work of Zhou et al., 2019 who propose a new approach, called Synchronous Bidirectional Neural Machine Translation (SB-NMT), to solve the unbalanced output problem.
Analysis on Translation Accuracy
As part of this work, the authors conduct an empirical study to assess the translation accuracy of the first 4 and the last 4 tokens in the NIST Chinese-English translation tasks. They make use of decoding in both directions; L2R denotes left-to-right decoding and R2L denotes right-to-left decoding for conventional NMT. The results of this analysis can be seen in table 1.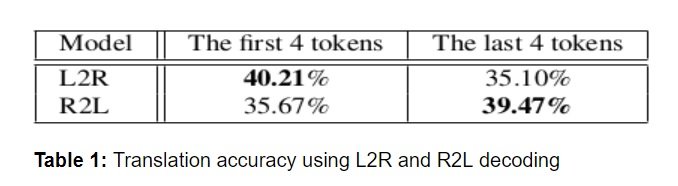 It can be seen that L2R performs better with the first 4 tokens, whereas R2L translates better in terms of the last 4 tokens. This is due to the use of unidirectional decoding where the output word predicted at any time-step t depends only on the previously generated outputs without making use of the future target-side context during translation.
It can be seen that L2R performs better with the first 4 tokens, whereas R2L translates better in terms of the last 4 tokens. This is due to the use of unidirectional decoding where the output word predicted at any time-step t depends only on the previously generated outputs without making use of the future target-side context during translation.
Approach
The authors introduce a novel approach, SB-NMT, to effectively and efficiently utilise bidirectional decoding. The SB-NMT model returns back to sequential text generation but does it from left & right at parallel. The SB-NMT model consists of one decoder that generates outputs in left-to-right and right-to-left directions simultaneously and interactively.
Two special labels, <l2r> and <r2l>, are used at the beginning of target sentences to denote the direction of decoding. Unlike conventional NMT, the decoder utilises the previously generated symbols from both directions to predict the next word at time step t. Thus, the SB-NMT model not only uses its previously generated outputs but also future context predictions from the R2L decoder.
For instance, the generation of y3 does not only rely on y1 and y2 but also depends on yn and yn−1 of R2L. The proposed decoder in the SB-NMT model is shown in Figure 1.
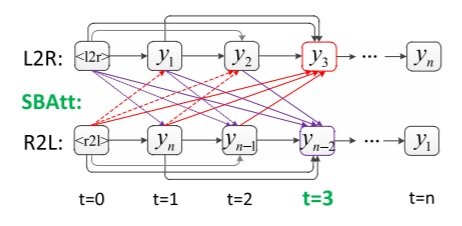
Figure 1: Illustration of decoder in the synchronous bidirectional NMT model
The SB-NMT model is built based on the Transformer (Vaswani et al., 2017). To incorporate this approach, they propose the following changes: They replace the multi-head intra-attention with a synchronous bidirectional attention (SBAtt) mechanism that is capable of capturing and combining the information from L2R and R2L decoding.Synchronous Bidirectional Dot-Product Attention: This attention model is based on scaled dot-product attention. It operates on forward (L2R) and backward (R2L) queries Q, keys K, values V. The computation for the new forward state is as follows:
 Integrating Bidirectional Attention into NMT: They make use of the Transformer (Vaswani et al., 2017) model with the decoder having bi-directional attention in place of masked self-attention. All bi-directional information flow inside of the decoder run in parallel and can make full use of the target-side history and future context during translation.
Integrating Bidirectional Attention into NMT: They make use of the Transformer (Vaswani et al., 2017) model with the decoder having bi-directional attention in place of masked self-attention. All bi-directional information flow inside of the decoder run in parallel and can make full use of the target-side history and future context during translation.
Synchronous Bidirectional Beam Search: Instead of the standard beam search, they make use of the synchronous bidirectional beam search process where one-half of the beam size decodes from L2R and the other half of the beam from R2L. At each time step, the best items of the half beams are selected and expanded simultaneously. In the final step, the translation result with the highest probability is given as the output.
Experiments and Results
Datasets: The proposed model is evaluated on three translation datasets with different sizes, including NIST Chinese-English (Zh→En), WMT14 English-German (En→De), and WMT18 Russian-English (Ru→En) translations.
Training: For training, they make use of the Bidirectional Transformer model along with the Adam optimiser ( β1 = 0.9, β2 =0.998 ). They use the same warmup and decay strategy for learning rate as Vaswani et al. (2017), with 16,000 warmup steps. During training, they employ label smoothing of value ls = 0.1. For evaluation, they use beam search with a beam size of k = 4.
If the target-side training data were used as simulated outputs of the other-side decoder, the only thing the model would learn to do would be to copy from the other decoder as much as possible and to do nothing on its own. In order to prevent this during training and inference, they make use of a two-pass method. First, they train teacher models for L2R & R2L. The 2 teacher models are used to decode the source inputs of bitext resulting in (x(t), yl2r(t)) and (x(t), yr2l(t)). During the second pass, these values yl2r(t) and yr2l(t) are used for decoding instead of y(t).
Baselines: They compare the proposed model against the following SMT and NMT systems - Moses (Koehn et al., 2007), RNMT (Luong et al., 2015), Transformer (Vaswani et al., 2017), Transformer (R2L), Rerank-NMT (Liu et al., 2016; Sennrich et al., 2016a) and ABD-NMT (Zhang et al., 2018).
Experiments demonstrate the effectiveness of the proposed SB-NMT model. They reported significant improvements over the Transformer model by 3.92, 1.49, and 1.04 BLEU points on NIST Chinese-English, WMT14 English-German, and WMT18 Russian-English translation tasks, respectively. During decoding, the SB-NMT model is approximately 10% slower than the baseline Transformer but two or three times faster than Rerank-NMT and ABD-NMT.
In summary
Zhou et al. (2019) propose a synchronous bidirectional NMT model that takes full advantage of both the history and future context provided by the bidirectional decoding states. The model adopts one decoder to generate outputs with left-to-right and right-to-left directions simultaneously and interactively. Based on the extensive experiments on NIST Chinese-English, WMT14 English-German and WMT18 Russian-English translation tasks, the SB-NMT model shows significant improvement over the Transformer model with acceptable speed loss during translation.
Author
Akshai Ramesh
Machine Translation Scientist