
Introduction
Looking at the evolution of Neural Machine Translation (NMT), from a simple feed-forward approach to the recent state of the art Transformer architecture, models are getting more and more complicated by involving a large number of parameters to fit a massive data well. As a consequence, over-parameterization is a common problem suffered by NMT models, and it is certainly a waste of computational resources. Some recent research (e.g. See et al., 2016 and Lan et al., 2020) demonstrates that a significant part of the parameters can be pruned without sacrificing translation performance. In this post, we take a look at a paper by Wang et at. (2020) which investigates the effect of weight pruning on Transformer models and how those redundant parameters can be re-utilized to further improve the model.
Parameter pruning and rejuvenation
The goal of the pruning strategy is to “cut” part of the parameters during the learning process by a certain ratio while the rest of the parameters can still preserve the accuracy of the model. More specifically, given a weight matrix W of N parameters and a predefined pruning ratio r, all the parameters are ranked by their absolute values and only the top (1-r) are kept. To remove the pruned parameters, a binary mask matrix (same size of W ) is applied on W: 0 for the pruned ones and 1 for the rest.
There are two pruning strategies:
(1) local pruning which is applied in each layer; and
(2) global pruning that compares parameters across different layers. After the pruning phase, they continue the training of the remaining network until convergence.
To further improve the model and make use of the pruned parameters, the pruned parameters are restored after the previous pruning and retraining. There are two rejuvenation strategies: zero and external initialization. The entire networks are retrained with one order of magnitude lower learning rate since the sparse network is already at a good local optimum. This strategy can efficiently avoid useless computations and further improve the performance of the model.Experiments and results
The experiments are conducted on four different language directions: English to German (En-De), Chinese to English (Zh-En), German to English (De-En) and English to French (En-Fr), using three of the most common NMT architectures: Transformer, RNNSearch and LightConv.
For the pruning experiments, they explore the effect of different ratios as shown in Figure 1. According to the results, around 20% of the parameters can be removed directly without any negative impact on the translation scores, and with continuous training on the pruned network the harmless pruning rate can increase up to 50%. Besides, different NMT architectures suffer over-parameterization to different extents, i.e. the Transformer model is less affected compared to RNN-based models. 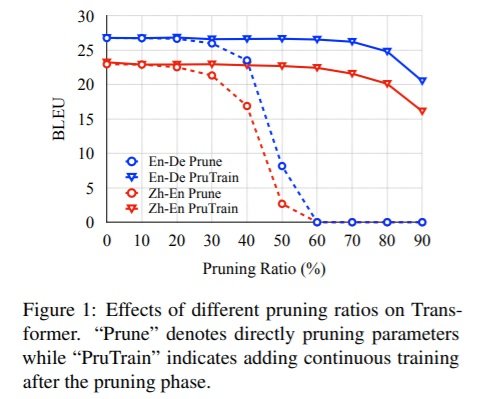 Based on the conclusion from Figure 1, they set the pruning ratio to be 50% to further compare the effects of different pruning and rejuvenation strategies. The conclusion is that local pruning outperforms the global pruning, but regarding the rejuvenation strategies, zero and external initialization perform similarly in terms of BLEU score.
Based on the conclusion from Figure 1, they set the pruning ratio to be 50% to further compare the effects of different pruning and rejuvenation strategies. The conclusion is that local pruning outperforms the global pruning, but regarding the rejuvenation strategies, zero and external initialization perform similarly in terms of BLEU score. 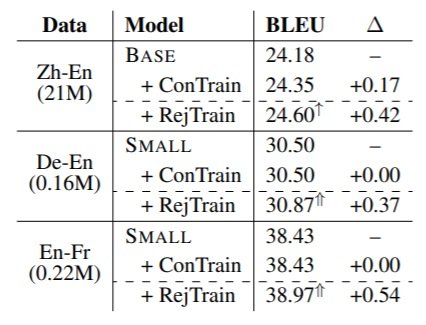
Table 1: Translation quality of Transformer model on different datasets varied in language pair and size.
To test the robustness of rejuvenation strategy (RejTrain) compared to continuous training (ConTrain), they also conducted experiments on data of different sizes and model architectures (Transformer, RNNSearch and LightConv). As shown in Table 1, RejTrain increases the BLEU scores in all cases, while ConTrain only leads to a slight improvement in the model trained with a large dataset (Zh-En). Regarding different model architectures, RejTrain achieves consistently better results on all models, but with ConTrain, RNN models get no improvement.Analysis
It is difficult to get further improvement with continuous training because models easily get stuck in a local optimum. However, pruning and rejuvenation training significantly changes the encoder representation and optimization direction during the training process, therefore, helps models to escape from local optimum. In terms of linguistic aspect, the rejuvenation strategy performs better on a lower linguistic level, capturing more lexical knowledge, thus improving the adequacy and fluency of translation.In summary
Wang et at. (2020) prove that current popular NMT models are all suffering from over-parameterization problems to different extents. Over-parameterization can be improved by using rejuvenation strategies. They conducted a series of experiments on different language directions, different model architectures and data sizes. The results demonstrate that the improvement made by the rejuvenation strategy is consistent in all cases.
Author
Dr. Jingyi Han
Machine Translation Scientist