
Introduction
For the second time in our blog series we look at Simultaneous Machine Translation (SiMT). In SiMT, translation begins before the full source input has necessarily been processed, reducing the delay as much as possible. By necessity this results in a trade off between delay and MT quality. This subject was discussed in a previous blog post. The full pipe line tries to mimic that of a human interpreter and therefore requires automatic speech recognition, whereas the paper which is our focus today, Arthur et al. (2021), is limited to the MT functionality. Interestingly, the evaluation focuses on BLEU and latency, instead of quality. Whereas in reality, a human interpreter is judged on whether they communicate the message content, while the ‘décalage’ varies according to various factors (language pair, interpreter preference, domain). This is necessarily very hard for MT, given that it has as yet no pragmatic dimension, in the linguistic sense.
The novelty
Research in SiMT revolves around strategies for determining when to read from the input or write to the output, with the read/write action triggered by an agent interaction with the NMT environment. Current strategies struggle with integrating the two. The work that is our focus in today’s blog, however, deploys Imitation Learning (IL) to optimize both and try to balance the quality-delay tradeoff. The novelty in this IL approach is that they use word alignments to produce their oracle actions, and that the approach uses scheduled sampling (SS) to expose both Programmer and Interpreter to the repercussions of incorrect decisions.
The approach
Their Neural Programmer Interpreter (NPI) approach uses a Markov Decision Process (MDP) for both the Programmer and Interpreter whereby the prediction taken as a particular timestep depends on previous predictions. The Programmer needs to determine the next action a given previous ones, while the Interpreter needs to execute the action generated by the Programmer- either READ of next input token, or WRITE to generate next target word.
The oracle for the IL needs to determine the required input for generating the output. The approach in this work uses word alignments to capture which words or phrases are required during a READ before moving to a WRITE, with conditions to ensure no WRITE at the beginning or READ at the end, by aligning first and last words. IL can suffer from exposure bias where the agent is only exposed to the situations which result from the correct actions, which means it cannot mitigate the consequences which result from incorrect actions. This work deploys scheduled sampling to address this shortcoming, exposing the agent to incorrect actions during training by artificially perturbing the actions, while still ensuring they are valid. The aim is to ensure that the Programmer and Interpreter are robust to their own incorrect predictions and those of each other.
To train the Programmer on training example (x,y,a) with scheduled sampling they create program a’ and translation y’ which are then used as input to the recurrent architectures of the Programmer and Interpreter decoders. The Programmer conditions each action on previous ones: the valid read/write actions for the Programmer are passed to the Interpreter and executed to give the states for conditioning the Programmer on. To train the Interpreter, it is exposed to valid perturbation a’’, created by permuting the READ/WRITE actions of program a, in order to ensure it is robust to incorrect actions and translations. The model parameters are learned by maximising the likelihood of oracle actions for both the Programmer and Interpreter (details in paper).
Experiments
The experiment is on 6 language pairs, covering a range of language families: German (DE), Czech (CS) and Arabic (AR), Hungarian (HR), Bulgarian (BG), and Romanian (RO). The datasets used for the main experiment are the IWSLT 2016 translation dataset (Cettolo et al., 2012) (for the first 3 language pairs), and SETIMES (Tyers & Alperen, 2010) for the other 3. (Also an experiment on a large amount of WMT data, see paper for details). The baseline is the wait-k policy (Ma et al., 2019) described in the aforementioned blog post, where k is a tunable variable representing the number of words to delay.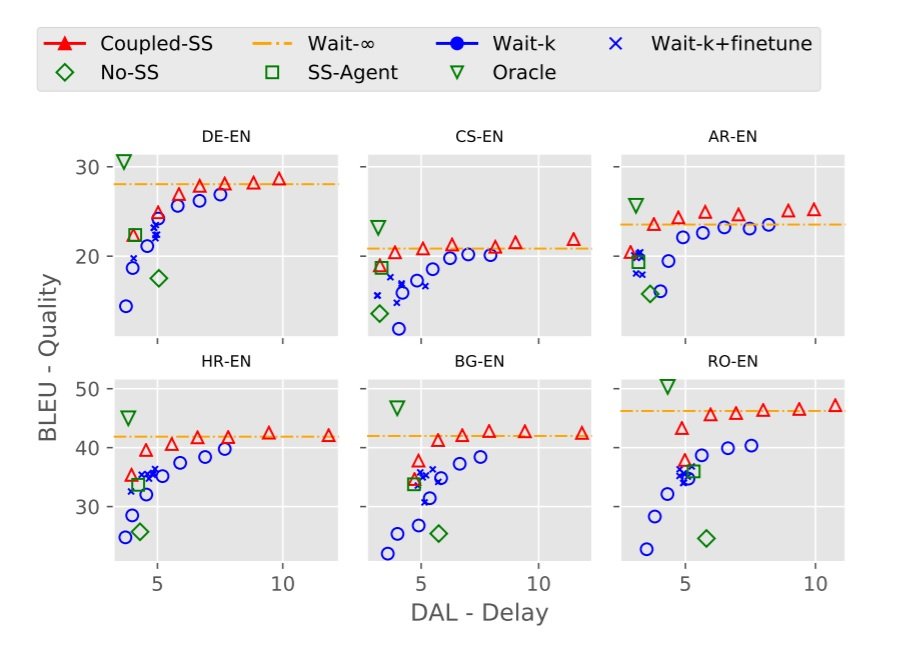 As can be seen from the above graphs, which plot the BLEU score against the delay, the proposed method performs better than the wait-k baseline in all settings. So training on the oracle actions improves the BLEU score and reduces the delay (differentiable average lag (DAL)).
As can be seen from the above graphs, which plot the BLEU score against the delay, the proposed method performs better than the wait-k baseline in all settings. So training on the oracle actions improves the BLEU score and reduces the delay (differentiable average lag (DAL)). 
Table 1: The comparison of our wait-k, our coupled-SS (Co-SS) and the oracle trajectory. A column shows a sequence of consecutive READ and WRITE. Here our proposed method is able to imitate the oracle well, by patiently waiting for sufficient input to produce a good translation. Red texts indicate place of translation error.
To give an intuition as to why this is, observe the table above, which displays the sequence of READ and WRITE actions for wait-k, coupled SS, and the oracle in each row (with setting DAL 4). Here the wait-k system is unable to correctly predict the negation (errors in red), as it appears later. It would seem that the oracle ensures the minimal required context from the word alignments.In summary
Arthur et al. (2021) deploy a novel IL coupled policy strategy, and attribute the effectiveness of their approach to 1) the scheduled sampling, and 2) the quality of the oracle actions. It results in an increase in BLEU score and a reduced delay. Just as the first MT systems were unacceptably poor substitutes for human translators, so will the first simultaneous MT systems be impoverished attempts to mimic human interpreters, and will largely fail in comparative settings. While they may at some point in the future help to interpret a few simple phrases in a bilingual setting, it is unimaginable that they can cover the full gamut of simultaneous communication in a live conference setting in the way a human interpreter does. But from a researcher perspective the fun is in the challenge.Tags:
Language Weaver
Author
Dr. Karin Sim
Machine Translation Scientist