
Introduction
In recent years, there has been a significant amount of research to improve the representation learning of neural machine translation (NMT). In today’s blog post, we will look at the work of Liu et al., 2019 who propose a novel approach called Shared-Private Bilingual Word Embeddings, to improve the word representations of NMT.
A word representation is a mathematical object associated with each word, often a vector. The NMT models make use of the word embeddings to capture the semantic and syntactic properties of words. NMT usually relies on 3-word embeddings:
- Input Embedding – Used to encode the source words
- Output Embedding – Used to encode the predicted target words
- Softmax Embedding – Vector representation that maps the probability distribution over the whole target vocabulary.
The Problem
The embedding layers occupy the majority of the model parameters (55%) and act as a limiting factor in improving the architectures especially in low resource scenarios where the models overfit easily due to a large number of parameters. The input and output embeddings are comparably isolated. The 2 embeddings are only interfaced through the softmax attention which causes the model to produce some unaligned translations.
The Approach
The authors propose a novel language-independent method, shared-private bilingual word embeddings, which represent a closer relationship between the source and the target embeddings. Inspired by previous works (Li et al., 2016; Zhang et al., 2017b; Li et al., 2018) to use shared vectors for representing similar words in the monolingual vector space, the authors propose to extend the idea to bilingual vector space and represent the similar source and target words with similar embeddings.
In Vanilla NMT, the source and target words are represented by two separate private vectors. In shared-private bilingual word embeddings, each vector consists of the shared features and the private features. The shared features capture the relationship between similar source and target-side words. The private features are used to learn the monolingual characteristics of the source and target-side words.
Shared Features
In order to map the similar words between the source and the target, the authors make use of 3 shared features:
1. Words with similar lexical meaning - Based on the alignment probability between the source and target words, the words which have the highest lexical similarity are mapped to each other and share common features. The alignment probability can be obtained by using the intrinsic attention mechanism (Bahdanau et al., 2015) or an unsupervised word aligner (Dyer et al., 2013).
For example, as shown in Figure 1 the English word “Long” and the German word “Lange”, which have similar meaning, tend to share more common features.
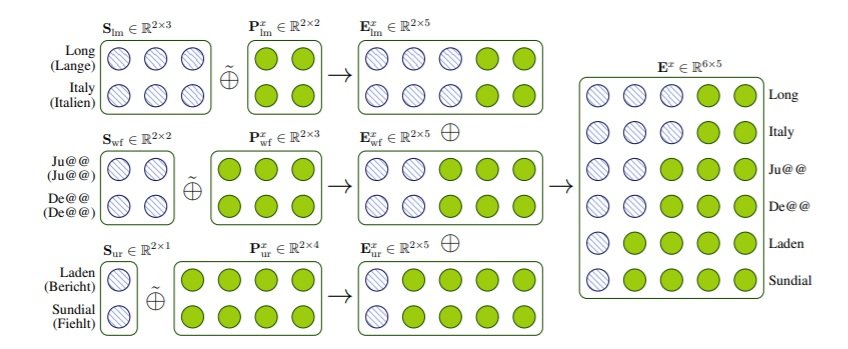
Figure 1: Assembling the word embedding with matrix concatenation operation
2. Words with the same word form - This category of words tends to share a medium number of features between the source and the target. For example, in figure 1 the subword “Ju@@” is present on both the source and target side and shares some common features.
3. Unrelated words - The source and target words that cannot be paired together are called unrelated words. In standard NMT, the word embeddings of low-frequency words are not trained properly and are treated as noises. Inspired by the frequency clustering methods proposed in Chen et al. (2016), the authors propose to share the possible features between the source and target words which are unrelated but have similar word frequencies.
Each source word shares the features with a single target word and vice versa. Also, it can be noted from figure 1 that each source and target side feature vector consists of private features to represent the monolingual characteristics. The word embeddings are formed in the following order :
Similar lexical meaning > Same Word Form > Unrelated words but similar frequency
The number of shared features of a word embedding is determined by their relationship. The final input embedding is formed by carrying out some matrix concatenation operation.
Experiments and Results
Datasets
The proposed approach is evaluated on six different languages using translation datasets of different sizes, including IWSLT17 { Arabic (Ar), Japanese (Ja), Korean (Ko), Chinese (Zh) } -> English (En), NIST Chinese-English (Zh-En) and WMT14 English-German (En-De) translations.Training
For training, they make use of the Transformer (Vaswani et al., 2017) using the base setting with the open-source toolkit THUMT (Zhang et al., 2017a). The Adam optimizer ( β1 = 0.9, β2 =0.998 ) is used to update the model parameters along with 4,000 warmup steps to adapt the variable learning rate.
They compare the effectiveness of the proposed approach with related works - Direct bridging (Kuang et al., 2018), Decoder WT (Press and Wolf, 2017), and Three-way WT (Press and Wolf, 2017). They make use of BLEU (Papineni et al., 2002) as the evaluation metric.
Findings
- Based on the BLEU scores, the experiments demonstrate that the proposed approach achieves the best performance with fewer model parameters (47.4-63.1% reduction) across all translation tasks.
- The proposed approach seems to work well across different data sizes. (230K - 4.5M)
- The experiments show that the approach is applicable to similar & distant language pairs. Using the layer-wise relevance propagation (Ding et al., 2017), the heatmap shows more concentrated attention in the shared-private approach as compared to Vanilla NMT which helps for better long-distance reordering.
- From the embedding visualisation shown in figure 2, it can be seen that the proposed approach helps in gathering both similar monolingual and bilingual words.
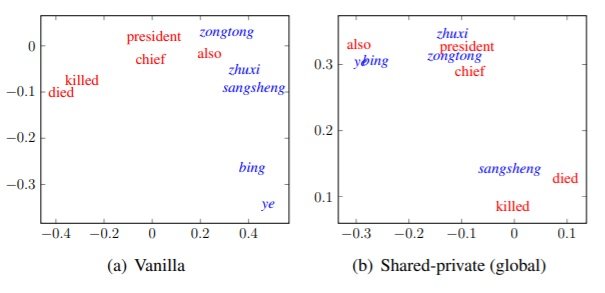
Figure 2: Two-dimensional PCA projection for Chinese(Zh) - English(En); shared-private approach seems to have both monolingual and bilingual words gathered closer compared to vanilla NMT.
In summary
Liu et al. (2019) propose a novel language-independent approach to improve the representation learning of NMT by introducing shared and private features. The use of shared features provides better alignment guidance between the source and the target along with a reduction in the number of parameters. The experiments show that the proposed approach outperforms Vanilla NMT and other related works resulting in an overall improvement in the translation quality.
Author
Akshai Ramesh
Machine Translation Scientist