
Introduction
Asian languages have always been challenging for machine translation (MT) tasks due to their completely different grammar and writing system. As we know, there are specific segmenters for Chinese and Japanese as there is no space between words in these languages. With regards to Korean, even though the words are separated by space, is a normal tokenizer used for western languages good enough for use with Korean? In this post, we take a look at a paper by Park et al. (2020), in which they conducted a set of experiments to explore the best tokenization strategy for different Korean NLP applications. We will only focus on the machine translation tasks here.
Linguistically-aware Korean segmenter
There have been several studies (Pinnis et al., 2017, Banerjee and Bhattacharyya, 2018 and Tawfik et al. 2019) that proposed to hybridize linguistic properties with data-driven tokenization strategies to improve MT performances. In this work, they tokenize the Korean data using MeCab-ko (trained on the Sejong Corpus morphologically annotated by many experts) from the smallest to the largest units: consonant and vowel (CV), syllable, morpheme and word, as the examples shown in Table 1. Then train MT engines with these data tokenized in different unit levels. Besides the linguistically-aware segmentation, they also compare MT performance trained with data tokenized by Byte Pair Encoding (BPE) and morpheme+BPE. To obtain the morpheme-aware subword, BPE is applied after MeCab-ko.
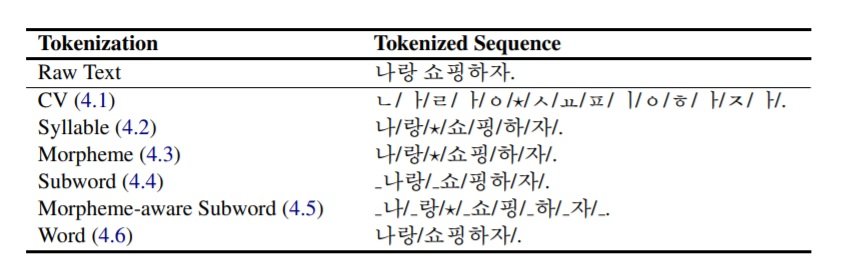
Table 1: An input sentence 나랑 쇼핑하자. ‘Let’s go shopping with me.’ is tokenized in different ways depending on the various tokenization strategies. Slashes (/) are token separators.
Experiments
The experiments were conducted with a Transformer network (6 blocks of 512-2048 units with 8 attention heads) in two language directions Korean-English (Ko-En) and English-Korean (En-Ko). The corpus used in experiments is the news data of 800K sentence pairs from a publicly available parallel corpus released by AL Hub, which includes various sources such as news, government websites and legal documents, etc: 784K for training, 8K for validation and 8K for testing.Results and observations
From Table 2, we can see that the model trained with morpheme-aware subwords of 32K performs better than other tokenization strategies in general for both language directions. Word level tokenization generates the most OOV (out of vocabulary), because the pre-defined vocabulary size is not enough to cover them all. Consequently, it delivers the worst MT quality. Morpheme tokenization also generates a relatively high OOV rate, but we can see that as the vocabulary size increases, the OOV decreases a lot, and the MT quality becomes more and more competitive. With the size of 64K, it is even better than the subword models. Besides, subword models contain up to 37% of tokens spanning morpheme boundaries in the test set, which implies that subword segmentation by BPE is not optimal and morpheme boundaries can be complementary to it.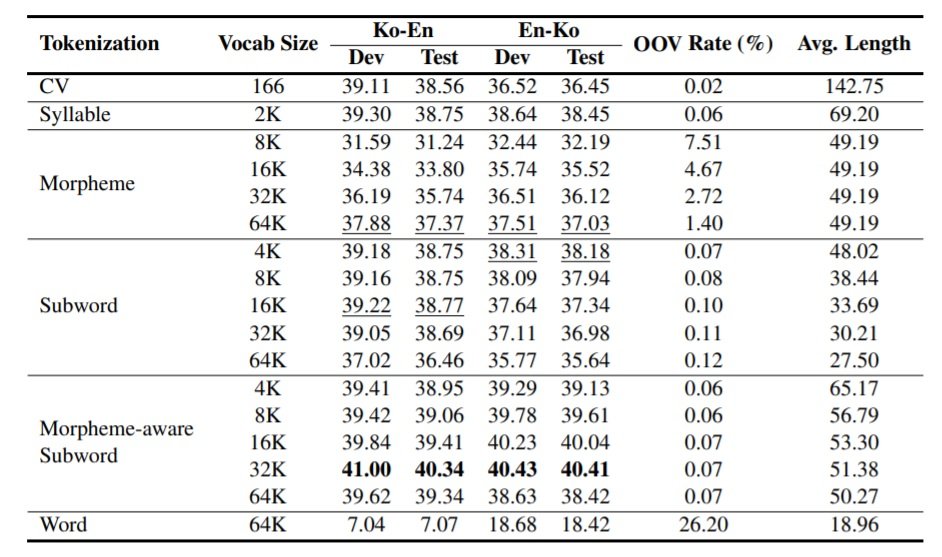
Table 2: BLEU scores of Ko-En and En-Ko translation models of various tokenization strategies. For English, all subword models are of the size 32K.
CV models have the smallest vocabulary within the entire corpus, so they show the lowest OOV rate. However, the MT performance is not as good as other models, they assume the reason is that a single consonant or vowel bears too much contextual information. According to the experiment results, the average number of syllables per Korean token between 1-1.5 show better results in both language directions.In summary
Regarding the MT experiments, Park et al. (2020) explore benefits and limitations of different Korean tokenization strategies and their impacts on machine translation quality. To sum up, morpheme-aware subword tokenization makes a better use of linguistics knowledge and statistical information, and its 32K model achieves the best BLEU scores compared to other vocabulary sizes. According to the results, it is convincing that it could be the best tokenization practice for MT with specific settings under low-resources scenarios.
Author
Dr. Jingyi Han
Machine Translation Scientist