
Introduction
Nowadays, Neural Machine Translation (NMT) delivers quite promising translation quality under the assumption that enough parallel data is available to build the engines. However, many languages have commonly used varieties and dialects which might not share that amount of parallel data. In this blog post, we take a look at the paper by Kumar et al. (2021) which proposes to adapt a Transformer-based MT system to produce language varieties that are close to the standard target language, without requiring direct parallel data between the source and the variety. This method also works for dialects and typologically related target languages.
Transfer-learning
The basic idea of this approach is to train a translation model A from a source language (SRC) to a standard language variety (STD) and fine-tune it with synthetic parallel data from SRC to another target variety (TGT) so that it can be adapted to do translation from SRC to TGT. To obtain the synthetic data, they apply the back-translation strategy: create a reverse translation model from STD to SRC using the same parallel data as model A. Then use this reverse STD to SRC model to translate a small TGT monolingual data to SRC assuming that the model can handle to some extent the differences between STD and TGT and produce useful “translation” in TGT.
The main contributions of this work compared with other related approaches are:
- This work is based on the Transformer architecture, but in order to deal with the vocabulary mismatch between STD and TGT during the finetuning, they separate the vocabulary from the MT model structure by replacing the decoder input and output with pre-trained word vectors. At each step in the decoder, they feed a pre-trained source word vector at the input, then the model predicts a word vector instead of using softmax to predict a probability over the vocabulary. The training is done by minimizing the von Mises-Fisher loss between the predicted vector and the pre-trained vector. During the decoding, at each step, the output word is generated by finding the nearest neighbor of the predicted vector inside the TGT word embedding table.
- Since the TGT monolingual data used to build synthetic data is too small, in order to obtain a good quality word embedding, they find the vocabulary overlap between STD and TGT data, then initialize the vector training on TGT data with the corresponding STD embedding, if available. Finally, they project the learned TGT embeddings into the same space as STD using identical tokens between STD and TGT data as supervision following the alignment method of Lample et al., (2018).
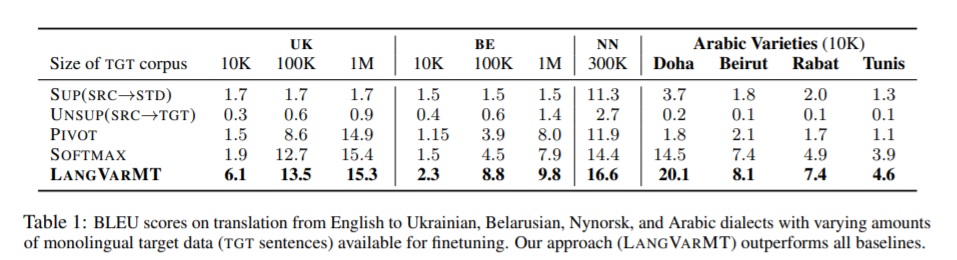
Experiments and results
- SUP(SRC→STD): train a standard transformer SRC→STD model, and consider the output of this model as TGT under the assumption that STD and TGT could be very similar.
- UNSUP(SRC→TGT): train an unsupervised MT model following Lample et al., (2018) in which the encoder and decoder are initialized with cross-lingual masked language models. These language models are first pre-trained on SRC data and then finetuned on TGT data.
- Pivot: train a UNSUP(STD→TGT) model using STD and TGT monolingual corpora as described above. During inference, translate the SRC sentence to STD with the SUP(SRC→STD) model and then to TGT with the UNSUP(STD→TGT) model.
- SOFTMAX: train a LANGVARMT with a softmax layer for prediction.
In Summary

Author
Dr. Jingyi Han
Machine Translation Scientist