
The Importance of Source Text in Automatic Post-Editing for Context-Aware Machine Translation
Introduction
For the first time in this blog series, we look at work on Automatic Post Editing (APE). Automatic post-editing detects error patterns and implements automatic error correction in the machine translated (MT) output, improving overall output quality. It does this by using translations post edited by humans as training data. This can be used as a way of incorporating the surrounding context, which is dropped in most sentence-level Neural MT (NMT) systems. Today’s blog post considers work by Pal et al., 2019, which incorporates the source text in an APE architecture, and also looks at how Wang et al., 2021 apply it to train a context-aware APE system. The latter show that incorporating the source improved accuracy in particular, a fact that they demonstrate is not captured by automatic evaluation methods.
Multi-encoder approach
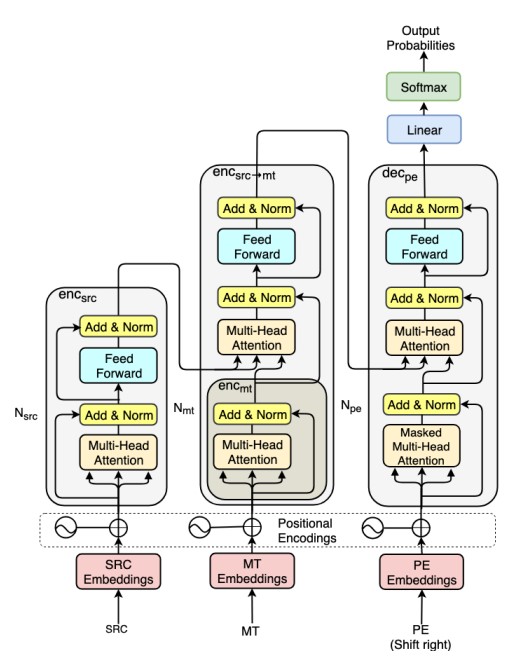
The work by Wang et al., 2021 is based on the Transference APE architecture of Pal et al., 2019, a three-way transformer architecture displayed below. Transference is a multi-encoder approach which conditions the post edit decisions on both the source and the machine translation output. It uses a transformer encoder block for the source (encsrc), followed by a second encoder combining src -> mt (encsrc->mt), which is effectively a standard decoder but without the mask. Here the internal encmt applies cross-attention over encsrc. This representation is then fed into the final decoder which generates the postedit, attending to the representations from encsrc->mt in addition to previously generated words. Their intuition is that the additional encoder attends over the source and MT, and informs the postedit, modelling error patterns and corrections.
Wang et al., 2021 apply Transference to document level, training on the data from Voita et al., 2019. The 30M pairs of English-Russian comprises a combination of context-aware and context-agnostic data, with the monolingual data including groups of 4 consecutive sentences. The synthetic training data for the inconsistent groups of sentences are created by roundtrip translating with a sentence-level model. Wang et al., 2021 include 2 checks to avoid the smaller context-aware model over correcting the output from the (larger) sentence-level system: a specially devised overcorrection penalty, and upweighting of better segments during training (see paper for details).
 Results
Results
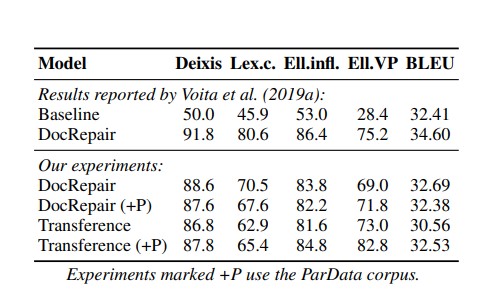
The baseline is a standard non-APE transformer base. The monolingual DocRepair APE baseline by Voita et al 2019 is a monolingual sequence to sequence model that aims to address inconsistencies resulting from sentence level NMT. It does not incorporate the source. The automatic evaluation of the 3 systems is performed using contrastive test sets, which focus on discourse-specific phenomena: deixis, lexical cohesion, ellipsis inflection, and elliptic verb phrases. The results in the table below show that the Transference does not improve over DocRepair for deixis and lexical cohesion categories. However, adding the source does improve the results on the ellipsis testsets. This is not surprising since they reflect omissions which are apparent in context. Both APE systems improve considerably over the non-APE baseline. Despite this we can see that the BLEU scores are similar across the systems, demonstrating yet again that it fails to adequately evaluate the output.
 For the human evaluation, the annotators were asked to rank how adequately the translation reflected the meaning of the source, with 3 sentences of preceding context and the English source test. For fluency they were asked to rank how fluent the in-context sentence was in terms of grammaticality, naturalness and consistency. Their results are replicated below and indicate that on fluency, both the monolingual DocRepair and Transference improve significantly over the non-APE baseline. The difference between the two on fluency rankings is not significant. On adequacy, however, we can see that DocRepair improves a little over Baseline, whereas Transference ranks significantly higher. This seems to be a clear indication that the source text is valuable in improving the accuracy of the MT output.
For the human evaluation, the annotators were asked to rank how adequately the translation reflected the meaning of the source, with 3 sentences of preceding context and the English source test. For fluency they were asked to rank how fluent the in-context sentence was in terms of grammaticality, naturalness and consistency. Their results are replicated below and indicate that on fluency, both the monolingual DocRepair and Transference improve significantly over the non-APE baseline. The difference between the two on fluency rankings is not significant. On adequacy, however, we can see that DocRepair improves a little over Baseline, whereas Transference ranks significantly higher. This seems to be a clear indication that the source text is valuable in improving the accuracy of the MT output.
 In summary
In summary
While previous context-aware APE has improved the consistency of MT output, Wang et al., 2021 build on the multisource transformer of Pal et al., 2019, and show through their evaluation that it is only by incorporating the source that the adequacy is substantially improved. They illustrate that BLEU scores are unable to measure the improvements, which are apparent from a combination of human evaluation and targeted discourse-specific testsets.
Tags:
Language Weaver
Author
Dr. Karin Sim
Machine Translation Scientist