
Introduction
Despite the high level of performance in current Neural MT engines, there remains a significant issue with robustness when it comes to unexpected, noisy input. When the input is not clean, the quality of the output drops drastically. In this issue, we will take a look at the impact of various types of 'noise' on the quality and we will discuss techniques proposed by Vaibhav et al. (2019) to improve the robustness of an NMT system.
Noises and their impact on Translation Quality
There can be several different types of noise, or errors, in any piece of text. It really depends on how it was written. These include, but are not limited to:- spelling or typographical errors (receive vs recieve)
- word omission
- word insertion
- repetitions
- grammatical errors (a ton of vs a tons of)
- spoken language (want to vs wanna)
- slang (to be honest vs tbh)
- proper nouns
- dialects
- jargon
- emojis
- obfuscated profanities (f*ing)
- OCR related errors ([4] vs 14], study vs st ud y)
- inconsistent capitalisation (change vs chaNGE)
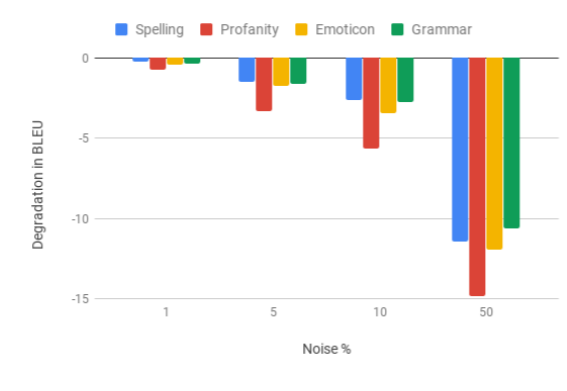 The impact of varying the amount of Synthetic Noise Induction on BLEU[/caption]
The impact of varying the amount of Synthetic Noise Induction on BLEU[/caption]
As we can see, obfuscated profanity is the biggest cause of the quality drop, followed by emoticon, spelling and grammar.
 Noisy text generation with back-translation; English text as an input[/caption]
Noisy text generation with back-translation; English text as an input[/caption]
How to make NMT robust?
To improve the robustness of a system, we can fine tune our system on a small set of noisy data, where available. Apart from that, we can also generate synthetic noisy data and train our system on that data. Vaibhav et al. (2019) proposed two noise induction techniques.Synthetic Noise Induction
For every token they introduce four different types of noises with some probability on both French and English sides of the corpus. The probabilities of error types were as follows: spelling (0.04), profanity(0.007), grammar (0.015) and emoticons (0.002). To simulate spelling error, they randomly add or drop a character in a given word. For grammar error and profanity, they randomly select and insert a stop word or an expletive and its translation on either side. And for emoticons, they randomly select an emoticon and insert it on both sides.Noise Generation through Back-Translation:
To induct back translation noise, they train MT systems in both directions (en-fr and fr-en) on different domain data. They then passed the text through such systems to get the resulting noisy text. Also, they added a subset of noisy data obtained from Michel & Neubig (2018) to train intermediate systems (adding noisy data made the text much closer to the style of noisy text, a similar but not same text is used for testing). The figure below describes the noisy text generation with back-translation. The figure shows English text as an input (French text can also be processed in a similar way). [caption id="attachment_14853" align="aligncenter" width="1071"] Noisy text generation with back-translation; English text as an input[/caption]