
Introduction
An important, and perhaps obvious feature of high-quality machine translation systems is that they preserve the meaning of the source in the translation. That is to say, if we have two different source sentences with slightly different meanings, we should have slightly different translations. However, this nuance can be a challenge, even for state-of-the-art systems, particularly in cases where source and target languages partition the “meaning space” in different ways. In this post, we will try to understand what are the language characteristics causing this meaning loss and discuss a few methods on how to reduce it in Neural MT.
Many-to-One Translation
Translation systems are typically many-to-one functions from source to target language, which in many cases results in important distinctions lost in translation. For example, take the following sentences:- By mistake, I cut off my finger with a knife.
- By mistake, I cut my finger with a knife.
- “गलती से मैंने चाकू से अपनी उंगली काट ली। (galatee se mainne chaakoo se apanee ungalee kaat lee.)
- “गलती से मैंने चाकू से अपनी उंगली काटकर अलग कर दी। (galatee se mainne chaakoo se apanee ungalee kaatakar alag kar dee.)
- “गलती से मैंने चाकू से अपनी उंगली काट ली। (galatee se mainne chaakoo se apanee ungalee kaat lee.)
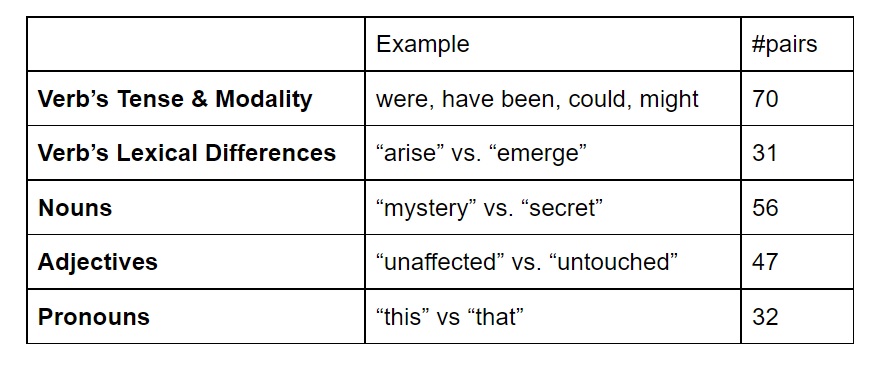
Languages differ in the way they explicitly mark meaning distinctions, making the task of translation systems even more difficult as we have to try to learn these. In general, it is difficult to model all small variations which are crucial (for many languages) to transfer correct distinction in the translated text. To evaluate the nature of the issue, Cohn-Gordon and Goodman (2019) explored a corpus of 500 sentence pairs in which distinct English sentences map to a single German translation. They identified a number of common causes for many-to-one translations. In the 500 segments, the following are the most common distinctions lost in the German translation.
Meaning Preservation
While languages differ in what distinction they are required to express, all are usually capable of expressing any given distinction when desired. Cohn-Gordon and Goodman (2019) proposed a method to reduce meaning loss by applying the Rational Speech Acts (RSA) model to the translation. RSA has been successfully used for modeling language pragmatics (Goodman and Frank, 2016), and recent works show its applicability in image captioning, another sequence generation NLP task.
In simple words, the RSA model is used to reduce many-to-one mappings, which consequently reduces meaning loss in the translation system. Cohn-Gordon and Goodman (2019) introduced a new inference algorithm to incorporate the RSA model in the translation process and showed a gain (+4%) in meaning preservation. Moreover, they obtained improvements in translation quality (+1 BLEU score), demonstrating that the goal of meaning preservation directly yields improved translations.