
Introduction
In this post, we will discuss the Transformer model (Vaswani et al. 2017), which is a state-of-the-art model for Neural MT. The Transformer model was published by Google Brain and Google Research teams in June 2017 and has been a very popular architecture since then. It does not use either Recurrent Neural Networks (RNN) or Convolutional Neural Networks (CNN). Instead, it uses attention mechanism and feed forward layers at various levels of the network to train the whole end-to-end pipeline. What does that mean?
Training Engines
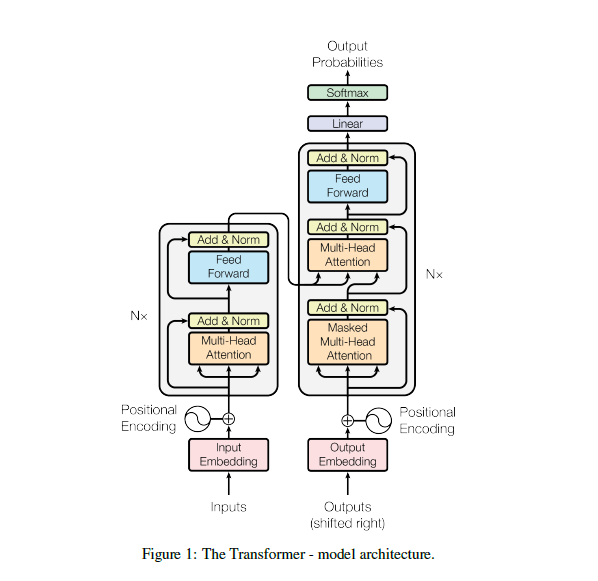
Similar to previous architectures for Neural MT, the Transformer also follows an autoregressive model based on Encoder-Decoder architecture. The Encoder consumes the input sentence and produces an encoded representation. The decoder generates the translation one token at a time using the encoded representation and the previously generated translation.What is Attention?
It gets difficult for a decoder to generate the translation by looking at the full encoded representation only once. When humans translate, they refer to the source sentence many times during the process (maybe even more than just the source sentence, see Issue #31). They also focus on different parts of the source sentence depending on the word or phrase being translated. To model such focus we have an 'attention mechanism' in Neural MT models. The attention mechanism provides additional information about which parts of the source are more relevant for the translation of the current token.
RNNs and CNNs use the respective architectures to train the encoder and decoder layers and use attention mechanism to model focus as a part of the decoder. The Transformer relies on attention mechanism to model all parts of the network. It uses attention mechanism to train encoder and decoder layers too and hence resulting in an architecture which does not need RNNs/CNNs. And for this reason, the title of the Transformer model paper is “Attention is all you need”.
Self Attention
In the Transformer model, the encoder is trained by attending to other words in the same sentence. The decoder is trained by attending to already generated words from the decoder and encodings from the source. As the model is autoregressive and depends on the previous generated words, the model takes care to not attending invalid or future positions by masking such invalid connections in the decoder. Because the words which are attended come from the same place (encoded words when training the encoder, or decoded words when training the decoder), the technique is called self-attention.Multi-Head Attention
Instead of using a single attention layer of size 512, the authors empirically found that using many small attention layers in parallel helps in training. Therefore, a base transformer model uses eight attention layers (of size 64) in parallel and concat them to form a multi-head attention layer (of size 512). It facilitates the model to focus on eight different heads of a sentence.Feed-forward Layer
To add more complexity in the model, in addition to attention layers, it also uses a position-wise fully connected feed-forward layer. Therefore, one layer in the encoder is composed of two sub-layers:- multi-head self-attention
- feed-forward layer
- masked multi-head self-attention
- multi-head attention which models focus
- feed-forward layer
How does it perform?
On English-German, the Transformer big-model achieved 28.4 BLEU and the Transformer base-model achieved 27.3 BLEU, compared to 26.36 by a CNN ensemble system, 25.16 by a CNN system and 24.6 by an RNN system.
On English-French, the Transformer big-model achieved 41.8 BLEU and the base-model achieved 38.1 BLEU, compared to 41.29 by a CNN ensemble system, 40.46 by a CNN system and 39.92 by an RNN system.
Therefore, in terms of quality, the model achieved better results on English-German and comparable results on English-French. In terms of training speed the transformer base-model was significantly faster. E.g. training the English-German base-model took 3.3x10^18 flops compared to 9.6x10^18 in CNN system (three times slower) and 2.3x10^19 in RNN system (seven times slower).
Recently, Lakew et al. (2018) compared RNNs and Transformer models on various neural MT tasks and found that the Transformer model consistently produces better translations than RNN.