
Introduction
In a few of our earlier posts (Issues #9 and #19) we discussed the topic of domain adaptation - the process of developing and adapting machine translation engines for specific industries, content types, and use cases - in the context of Neural MT. In general, domain adaptation methods require retraining of neural models, using in-domain data or infusing domain information at the sentence level. In this post, we’ll discuss the recent developments in updating models as they translate, so-called on-the-fly adaptation.
Neural MT and on-the-fly adaptation
Approaches to MT can be categorised as parametric (Neural MT) and non-parametric (Statistical MT). Though generally producing better output, parametric models are known to be occasionally forgetful, i.e. they may not use information seen in the training data (caused by a parameter shift during training). On the other hand, for all of their faults, non-parametric models do not have this forgetfulness. Thus, if there was a way to combine the two, we could have the best of both worlds - generalisation ability, and robustness. There have been attempts to combine non-parametric information with Neural MT but it has only been successful on very close domains, possibly due to over-reliance on sentence level retrieval. On-the-fly adaptation - adapting the model (updating the model parameters) on-the-fly for each source sentence with similar sentence pairs retrieved from the training corpus - is a technique that is growing in popularity for infusing non-parametric information into Neural MT models.Improved Retrieval
Bapna and Firat (2019) proposed an improved n-gram based retrieval technique that relies on the phrase level similarity, allowing the model to retrieve similar segments that are useful for translation even when overall sentence level similarity is very low. They compared their proposed methods 1) Inverse Document Frequency (IDF) based N-gram Retrieval 2) Dense Vector based N-gram Retrieval, with a baseline, based on simple IDF similarity score. The IDF score of a token t is defined as: 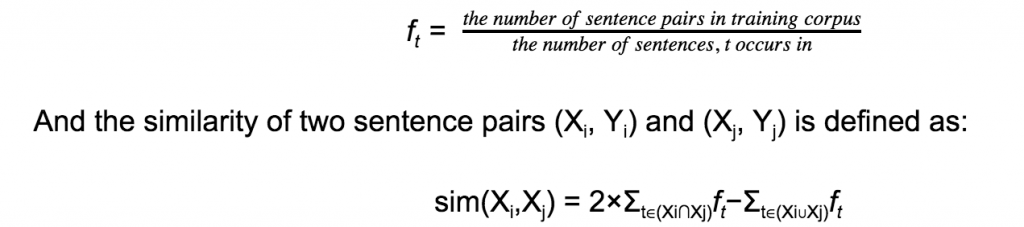
IDF based N-gram Retrieval
In this method, they extract all possible n-grams for any given sentence and use these n-grams to represent the sentence. N-grams at even positions (in the sequence of all n-grams) are skipped to reduce the number of n-grams. The set of neighbours for a sentence X is the set of all sentences in the training data that contains a n-gram that maximises the n-gram similarity (IDF) with any n-gram in the reduced n-gram-set representing X. To capture phrases of different lengths, they used multiple n-gram widths.
Dense Vector based N-gram Retrieval
The idea behind using a dense vector based similarity is to exploit the semantic similarity and incorporate the relevant information in the translation process. Bapna and Firat (2019) used a pre-trained Transformer model to generate subword level dense vector representation of a given sentence. The representation of each n-gram is then defined as the mean of the vector representations of constituent subwords. They use L2 distance (Euclidean distance) of n-gram representation as retrieval criterion.
Conditional Source Target Memory
Conditional Source Target Memory (CSTM) is the encoded representation of the retrieved target segments from the above retrieval system. The CSTM encoding is generated using the following steps-- The retrieved source segment, Xi, is encoded using Transformer encoder. The encoder representation of the current source is then combined using decoder style cross attention.
- The retrieved target, Yi, is encoded in a similar manner, attending the encoded representation of retrieved source generated in the previous step.
Gated Multi-Source Attention
The CSTM is incorporated in the NMT decoder using gated multi-source attention. It is similar to the Transformer decoder with attention, except it also attends CSTM in every cross-attention layer with encoder outputs.Non-Parametric Adaptation
First, Bapna and Firat (2019) trained a baseline model combining multiple datasets (WMT, OpenSubtitles, IWSLT, and JRC-Acquis). Using semi-parametric approach, then a domain-adapted model (single model for all the domains) was trained with n-gram retrieval, CSTM, and the Gated Multi-Source Attention described above. For scalability reasons, the retrieval system was restricted to in-domain training corpus, i.e. neighbours for all training, development and test sentences in the JRC-Acquis corpus were retrieved from the JRC-Acquis training split, and similarly for the other datasets. They reported best accuracy, using “n-gram dense vector retrieval” with a gain of 10 BLEU points on JRC-Acquis, 2-3 BLEU points on OpenSubtitles and IWSLT, and a moderate gain of 0.5 on WMT14.
The success of semi-parametric approach opens up the doors for non-parametric adaptation. The biggest advantage of the non-parametric approach is that we can train a single massively customisable model which can be adapted to any new domain at inference time, by just updating the retrieval dataset.
To compare the effectiveness of the approach a baseline (semi-parametric adapted) model was trained with only WMT dataset. To apply non-parametric adaptation for a new domain, the retrieval system of this baseline system is updated with the target domain and used to adapt the model at inference time (on-the-fly adoption without re-training). They compared the non-parametric adaptation with the traditional fine-tuning and found that the non-parametric approach is capable of adapting to the new domains as it outperforms the fully fine-tuned models by 1-2 BLEU points.