Introduction
Back in Issue #15, we looked at the topic of document-level translation and the idea of looking at more context than just the sentence when machine translating. In this post, we will have a look more generally at the role of context in machine translation as relates to specific types of linguistic phenomena and issues related to them. We review the work by Voita et al. (2019) where they observed various issues arising from the absence of context. They also proposed an approach to resolve such issues.
Context Related Issues in English-Russian Translation
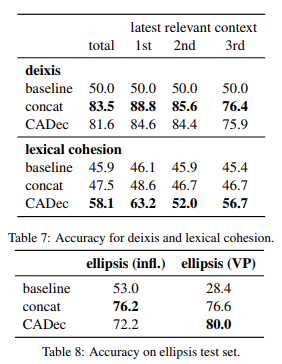
To analyse the errors related to contextual information, Voita et al. translated a test set of 2,000 pairs of consecutive sentences using a baseline transformer model. They used English-Russian as part of the OpenSubtitles data for the test and training the engine. They conducted both evaluation at sentence level and evaluation in context. The authors found that in 7% of the cases, the translations were bad in context even though the individual sentence translations in the pairs were good. In these cases, the authors further analysed the types of errors and found out various phenomena - deixis, ellipsis, lexical cohesion, ambiguity, anaphora etc. (click each one for a description!) - as reported in the table below.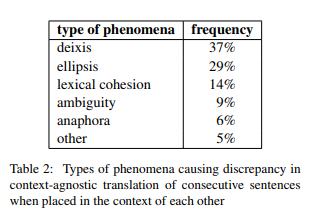 The main cause of deixis errors were T-V distinction (informal vs formal language) and the speaker's gender. In ellipsis, morphological form of words and omission of the main verb was the primary cause of the issues. Some examples of such issues are given in the following figures.
The main cause of deixis errors were T-V distinction (informal vs formal language) and the speaker's gender. In ellipsis, morphological form of words and omission of the main verb was the primary cause of the issues. Some examples of such issues are given in the following figures.
Example Ellipsis

Example Lexical Cohesion

Proposed CADec Model
The context-aware model (CADec model) is a two-pass framework: the first part of the model is a context-agnostic model (base model), and the second one is a context-aware decoder (CADec). The CADec is trained to correct translations given by the base model using contextual information. The base model is trained on sentence-level data and then fixed. It is used only to sample context-agnostic translations and to get vector representations of the source and translated sentences. CADec is trained only on data with context. To generate context data, each long group of consecutive sentences is split into fragments of 4 sentences, with the first 3 sentences treated as the context.
The baseline model (base model) is a simple (context-agnostic) transformer model and it is trained on 6 million pairs of English-Russian data. The CADec decoder is similar to the original transformer decoder trained with 1.5 million instances having up to three context sentences. Another baseline (concat model) is produced by concatenating the context data and training a simple transformer model.
Results
In terms of BLEU scores, the base model obtained 32.40 BLEU, the concat model obtained 31.56 BLEU and the CADec model obtained 32.38 BLEU. The authors also evaluated the ability of various models in resolving contextual issues. We can see the accuracy of the three models (base, concat and CADec) on various contextual phenomenon in the following table. Both the CADec and the concat model improves upon the base model, however, CADec can be said to be a better model overall as it also manages to preserve the same BLEU as baseline (32.38 vs 32.40), therefore, no degradation in general quality.