
Introduction
Interlingua Neural MT (NMT) architecture treats the whole NMT system as separate independent blocks per language which can be combined to form a multilingual NMT system. With this architecture we can have a universal source language sentence representation which can be used to translate in any target language. This also enables translation among the languages present in the system even though the system is not specifically trained on that language pair, by way of introducing zero-shot translation.
Recently, Escolano et al. proposed an interlingua NMT architecture with the flexibility to add more languages incrementally, thus avoiding the need to train the whole system again when requiring a new language translation. We had a quick overview of this architecture in our issue #38 and we revisit it again in more detail here.
In Neural MT, an “encoder” is the part of the network that for a given input sentence produces a sentence representation. Analogously, a “decoder” is the part of the network that produces the tokens of the target sentence using the source sentence representation. In a typical NMT system the encoder and decoder are trained and optimized for a language pair instead of individual languages. The source representation is always dependent on the target language.
However, in the interlingua NMT architecture, the encoder and the decoder are considered as independent modules. We train each language in such a way that the representations obtained for that language are independent of the other. Therefore, we convert input text in an interlingua representation, which can later be used to translate into one or more other languages. Each language and module has its own weights independent from all the others present in the system. This independence between modules helps when adding new languages without training previously available languages in the system.
Autoencoder
Autoencoder consists of a generative model that is able to generate its own input. In interlingua NMT, autoencoder is trained to read the source sentence and generate or reconstruct the same. This is different from the usual encoder-decoder in neural MT where we train the system to encode the source and generate the target.Joint Training
Given two languages X and Y, the objective is to train independent encoders and decoders for each language. Therefore, we train two encoders Ex and Ey and two decoders Dx and Dy. The training schedule combines two tasks (auto-encoding and translation) and the two translation directions simultaneously by optimizing the following loss:
L = Lxx + Lyy + Lxy + Lyx + d
Where Lxx and Lyy correspond to the reconstruction losses of both language X and Y (autoencoder loss), Lxy and Lyx correspond to the loss measuring token generation of each decoder (translation loss). d corresponds to the distance metric between the representation computed by the encoders. The d forces the representations to be similar without sharing parameters while providing a measure of similarity between the generated spaces.
Adding a New Language
Since parameters are not shared between the independent encoders and decoders, the architecture enables adding new languages without the need to retrain the current languages in the system. Let’s say we have already trained X and Y and we want to add a new language Z. To do so, we require to have parallel data between Z and any language in the system. In this case, we need either Z−X or Z−Y parallel data.
Let’s say we have Z-X parallel data. Then, we can set up a new bilingual system with language Z as source and language X as target. To ensure that the representation produced by this new pair is compatible with the previously jointly trained system, we use the previous language X decoder (Dx) as the decoder of the new Z-X system and we freeze it. During training, we only update the layers belonging to language Z. After successful training, we now have a new encoder (Ez) for language Z.
Introducing encoder Ez enables zero-shot translation for the language pair Z-Y. The system has not seen Z-Y parallel data, however we can translate from Z to Y by using the encoder Ez and decoder Dy which is already in the system.
The figure below illustrates this where we had language X and Y in the system and we introduced language Z encoder. 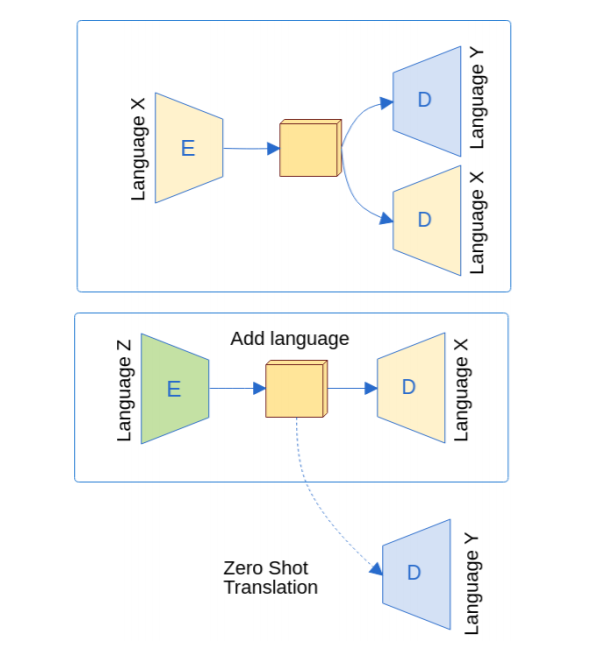 This is different from Johnson et al. (2017) (covered in issue #6), where a special token denoting the desired target language is provided with the input source, thereby obtaining the source representation corresponding to the desired target language. However, here the source representation is independent of the target language. Furthermore, in Johnson et al. (2017) the system was trained simultaneously for all languages in the system instead of adding languages incrementally.
This is different from Johnson et al. (2017) (covered in issue #6), where a special token denoting the desired target language is provided with the input source, thereby obtaining the source representation corresponding to the desired target language. However, here the source representation is independent of the target language. Furthermore, in Johnson et al. (2017) the system was trained simultaneously for all languages in the system instead of adding languages incrementally.
How does it perform?
The system obtained 12.56 and 14.82 BLEU points compared to 11.85 and 14.31 BLEU points by the baseline transformer model for English to Turkish and Turkish to English language pairs respectively. Therefore, a slight improvement (0.5+ BLEU) over the baseline for both language pairs.
In zero-shot setting, when comparing the performance of Kazakh-Turkish to a pivot transformer system which consists of translating from Kazakh to English and from English to Turkish, the system obtained 4.36 BLEU compared to 4.74 BLEU obtained by the pivot transformer system. Therefore, a slight decrease over the baseline in the zero-shot scenario.