Pivot-based Transfer Learning for Neural MT between Non-English Languages
Introduction
Neural MT for many non-English languages is still a challenge because of the unavailability of direct parallel data between these languages. In general, translation between non-English languages, e.g. French to German, is usually done with pivoting through English, i.e., translating French (source) input to English (pivot) and English (pivot) into German. However, pivoting requires doubled decoding time and the translation errors are propagated or expanded via the two-step process.
One approach to build such a direct system is to train a multilingual engine involving all three languages. In this blog post, we will have a look at pivot based transfer learning with pre-training, a recently proposed approach by Kim et al. (2019), which performed better compared to the multilingual model training.
Pivot Based Transfer Learning
- Pre-train a source-pivot model with a source-pivot parallel corpus and a pivot-target model with a pivot-target parallel corpus.
- Initialize the source-target model with the source encoder from the pre-trained source-pivot model and the target decoder from the pre-trained pivot-target model.
- Continue the training with a source-target parallel corpus.
1 - Step wise pre-training of a single model for different language pairs
In this method, they train a single NMT model for source-pivot and pivot-target in two consecutive steps. In step 1, they train a source-pivot model with source-pivot parallel corpus and in step 2, they continue training with a pivot-target parallel corpus, while freezing the encoder parameters of step 1. In this way, the encoder is still modelling the source language although we train the NMT model from pivot to target.2 - Pivot Adaptor to smoothly connect pre-trained encoder and decoder
In this method, they learn a linear mapping between the two representation spaces (source encoder and the target decoder ) with a small source-pivot parallel corpus. With this mapping, the source encoder emits sentence representations that lie in a similar space of the pivot encoder. Therefore, it is better suited for our target decoder as it is trained with pivot-target corpus and expects pivot language encodings.3 - Cross-lingual encoder training via auto-encoding of the pivot language
In this approach, they modify the source-pivot pre-training procedure to force the encoder to have the same mathematical space for both source and pivot languages. They achieve this by an additional de-noising auto-encoding objective from a pivot sentence to the same pivot sentence. The encoder is fed with sentences of both source and pivot languages, which are processed by a shared decoder that outputs only the pivot language. When feeding the pivot language sentence, some noise is introduced so that the encoder learns linguistic structures, grammatical constructs and word order, etc., instead of learning to copy.Results
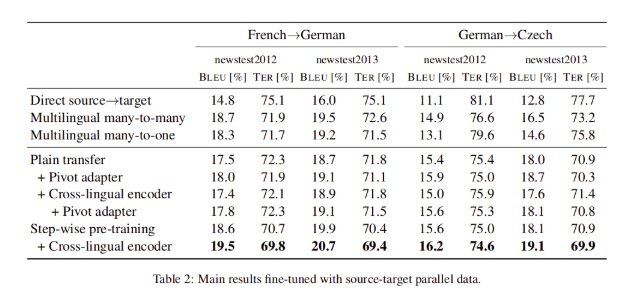
The results are given in the table below. We can see that step-wise pre training obtain similar results for the French-German system and better results for the German-Czech system when compared with the many-to-many multilingual approach. And when we combine step-wise pre training and cross-lingual encoder, the approach obtains better results for both language pairs.