
Introduction
Although current research has explored numerous approaches for adapting Neural MT engines to different languages and domains, fine-tuning remains the most common approach. In fine-tuning, the parameters of a pre-trained model are updated for the target language or domain in question. However, fine-tuning requires training and maintenance of a separate model for each target task (i.e. a separate MT engine for every domain, client, language, etc). In addition to the growing number of models, fine-tuning requires very careful tuning of hyper-parameters (eg. learning rate, regularisation, etc.) during adaptation, and is prone to rapid over fitting. This sensitivity even worsens for the high capacity (bigger size) models. In this post, we will discuss a simple yet efficient approach to handling multiple domains and languages proposed by Bapna et al., 2019. 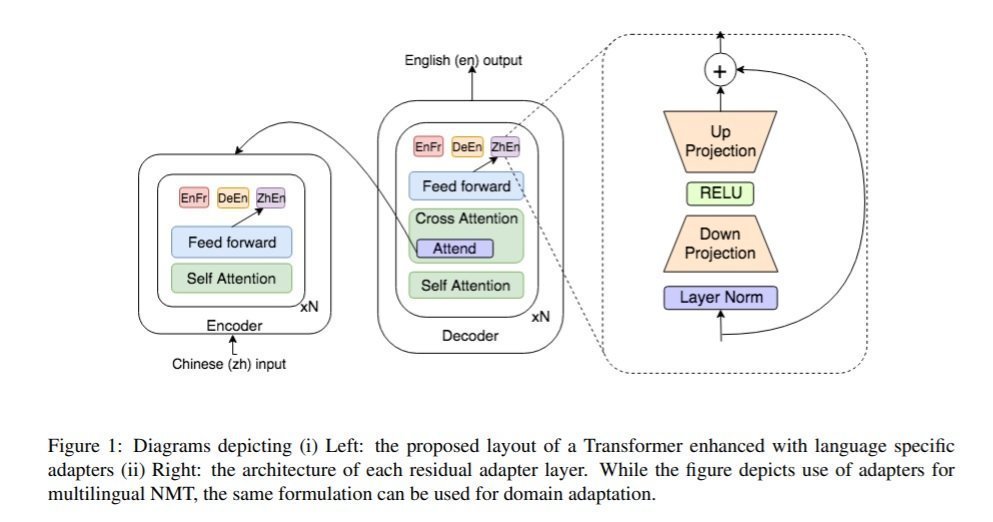
Approach
The proposed approach consists of two phases:- Training a generic base model
- Adapting it to new tasks adding small network modules
Performance
In their paper, Bapna et al. (2019) evaluated the performance of the proposed approach with two tasks: (i) Domain adaptation and (ii) Multilingual NMT (MNMT).Domain Adaptation
Using adapters for domain adaptation, they follow the two step approach:- Pre-training: Pre-train the NMT model on a large open-domain corpus. Freeze all the parameters of this pre-trained model.
- Adaptation: Inject a set of domain-specific adapter layers for every target domain. Only these adapters are then fine-tuned to maximize performance on the corresponding domains.This step can be applied any time a new domain is added to the model.
Multilingual NMT
In MNMT, the proposed adapters are used to improve the performance on the languages learnt during pre-training i.e. in contrast to the domain adaptation, we can't add new languages during the adaptation step. The following two step approach is used for MNMT-- Global training: Train a fully shared model on all language pairs, with the goal of maximising transfer to low resource languages.
- Refinement: Fine-tuning language pair specific adapters for all high resource languages, to recover lost performance during step 1. This step can only be applied for language pairs learned during global training.