
Introduction
Paraphrasing is common in human languages, as a way to talk about the same thing in different ways. There are many possible sentences that could be used to express the same meaning. From an MT perspective, we wanted to train systems that could not only translate sentences that bear similar meaning in one language into a sentence in another language, but also translate into different sentences that bear the same meaning. In this post we will discuss the work done by Zhou et al., (2020). [caption id="attachment_16368" align="aligncenter" width="548"]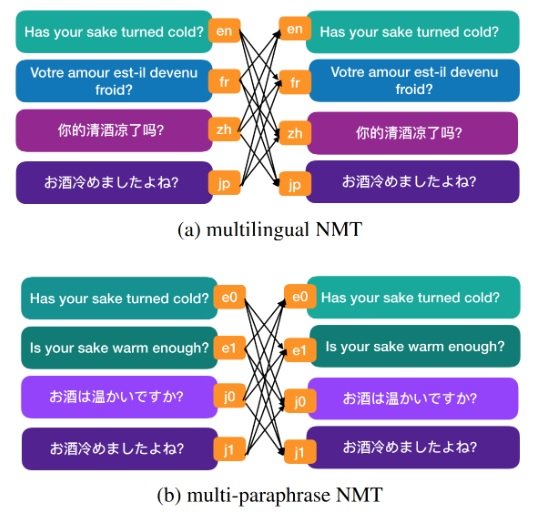 Figure 1. Translation paths in multilingual NMT and multi-paraphrase NMT.[/caption]
Figure 1. Translation paths in multilingual NMT and multi-paraphrase NMT.[/caption]
Multilingual NMT
The invention of neural machine translation (NMT) allows us to build an MT system that can translate from multiple languages into multiple languages. This is usually done by specifying which target language is to be translated to on the source side of translation pairs that are used for model training. Fig. 1 (a) shows the translation paths and how training sentence pairs are prepared in multilingual NMT. A sentence in one language will be paired with sentences that bear the same meaning in other languages.Multi-paraphrase NMT
The idea of multi-paraphrase MT is to improve translation performance by adding more ‘paraphrases’ in the training. Using the same Multilingual NMT setup, the paraphrases could be added either on the source side or target side, or both. This gives the NMT system more examples of translations of one source sentence. If only two languages are involved, both NMT and statistical MT could be used to train the systems. However, if there are more than two languages, only NMT can be used in the training of MT systems.Experiments and Results
Datasets
For the ‘paraphrase’ corpora, French-to-English Bible corpus is used. There are 12 versions of the English Bible and another 12 versions of the French Bible. As Bible corpora are well aligned structurally, there are 24 paraphrases in total for each sentence in the curated corpus. In the experiments the systems are trained to translate from French to English.Results
The experimental results show that adding paraphrases in the training increase the MT performance, as we expected. It also shows that adding paraphrases on the source side is more beneficial than adding target side paraphrases. Adding on both sides is also better than adding on either side, although this is also expected. One interesting result is that adding more languages in the training of one MT system does not outperform the system training on French and English corpora only. We might need to investigate more on this result, which is related to zero-shot MT. It is also good to see the resulting translations exhibit more diversity lexically and with expressiveness.