
Introduction
In general, neural networks utilise the same amount of compute, independent of the inherent complexity of the input. In this post, we’ll discuss a strategy proposed by Bapna et. al., (2020) adapting the compute-requirement in Neural MT depending on available compute budget. We will also discuss the effect on the translation quality. 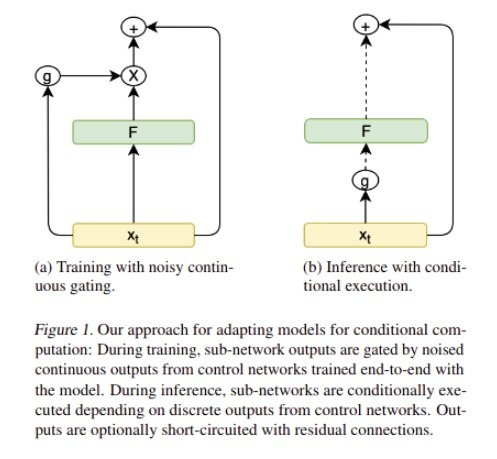
Adapting models for conditional computation
In the proposed method, the authors modify the sequence-to-sequence architecture (Transformer) for conditional computation, named Conditional Computation Transformer (CCT) i.e. the proposed models are computation aware and capable to adapt for a required compute budget. They first modify the Transformer architecture making each set of operations conditionally executable - the model selectively executes certain sub-networks of the computation graph - based on the output of a learned control network (Figure-1). Then they train this model for a multi-task setting, where each task corresponds to a future possible compute budget. This way, it allows having a single model that can be controlled to run on different computation-quality trade-off curves.
The control network is simply a single layer feedforward network that takes a single hidden state of the Transformer model as an input and produces a probability distribution for that layer if it should be executed or not in the current computation graph. For implementation details, please see the mathematical description in the paper. 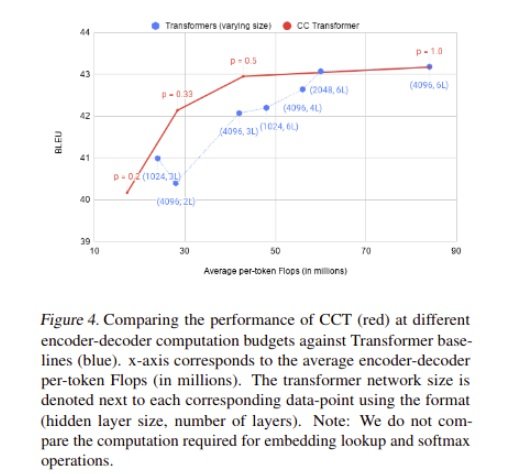
Experiments on Neural MT
They evaluated the proposed approach on the WMT’14 English-French translation task. The baseline was trained using a Transformer Big model and for smaller budget baselines they reduced the transformer capacity following two approaches: (i) Reducing the model depth by reducing the number of layers and (ii) Reducing the model width by reducing the hidden dimension of the feed-forward layers.
They compared the baselines against a single CCT model operating at different compute budgets with a maximum capacity equivalent to Transformer Big. From above figure-4, the results suggest that CCT is competitive with Transformer Big even when operating at half of its computation budget. At smaller computation budgets, CCT improves 1-1.5 BLEU points over smaller baselines.