
Overview
In this post, we will look into the task of predicting the quality of machine translation, its applications, and how research in this area has been reshaped in the context of neural machine translation. More specifically, we will discuss the shift from quality estimation models devised independently from the machine translation systems, to models that resemble neural machine translation systems, and finally to using the neural machine translation system itself as a quality estimator.What is Quality Estimation?
Quality Estimation (QE) for Machine Translation (MT) is the task of automatically predicting the quality of a text translated by an MT model without access to a reference translation or a human evaluator. The applications of QE include selecting translations of acceptable quality for human post-editing (similar to a fuzzy match score in translation memories); selecting translations that are good enough for use as is, for example in downstream tasks like data augmentation or information extraction; informing end-users of unreliable translations; selecting one among translations from multiple MT systems; etc. An important feature of QE is therefore that it enables different types of evaluation, focusing on different definitions of quality and targeting different types of users and applications. QE has the potential to make MT systems more useful in practice.How is Quality Estimation done?
Since the first proposal in 2004, QE approaches have been traditionally framed as a supervised machine learning problem. In other words, a large enough number of examples (a few thousand) of source text and its machine translations are collected and labelled for quality by human experts, and this is used as training data to build prediction models. The models can vary substantially; what they all have in common is that they extract information from the source text and the translation in an attempt to measure how complex the source text is (e.g. number of words, depth of its syntactic tree), how fluent the translation is (e.g. language model score), and how adequate the translation is with respect to the source text (e.g. source-translation alignment probabilities). The specific definition of quality for an application at hand is implemented through these labels, e.g. a number in 0-100 (how much editing is needed) or a binary score (reliable/unreliable), as well as through information extracted from the source and translated data to represent source complexity, target fluency and source-target adequacy. The labelling and prediction in QE can be done at different granularity levels: word, phrase, sentence, paragraph, document, depending on the application envisaged.
QE approaches evolved from using traditional machine learning algorithms on top of a large number of statistical and linguistic features extracted through dedicated modules to deep, neural approaches where features are automatically learned from the source-target examples. A comprehensive description of approaches to QE can be found in this book by Specia et al. (2018).
Quality Estimation in the neural MT era
The dominant approaches for QE for neural MT (NMT) output also use neural architectures which to some extent resemble NMT architectures. The first breakthrough was the Predictor-Estimator approach, which consists of two modules: the Predictor is trained using bidirectional recurrent neural nets on a large number of source-human translation pairs (same type of data used to train NMT models) to learn representations on what good translations should look like, whereas the Estimator takes such representations for labelled quality estimation data and trains another model to predict quality scores, for example by encoding word representations using a recurrent neural network. More recently, the Predictor has been replaced by more powerful pre-trained word or sentence-level representations, the most effective of which are also learned using parallel data. This approach was the winner in the WMT19 QE shared task. Given the clear similarities between the QE and NMT architectures, and often the data used to build both types of models, we asked ourselves the following question: are these QE models learning anything different from what is already known to the NMT models? In other words, do we need to train separate QE models or can we rely solely on information already provided by the NMT models?
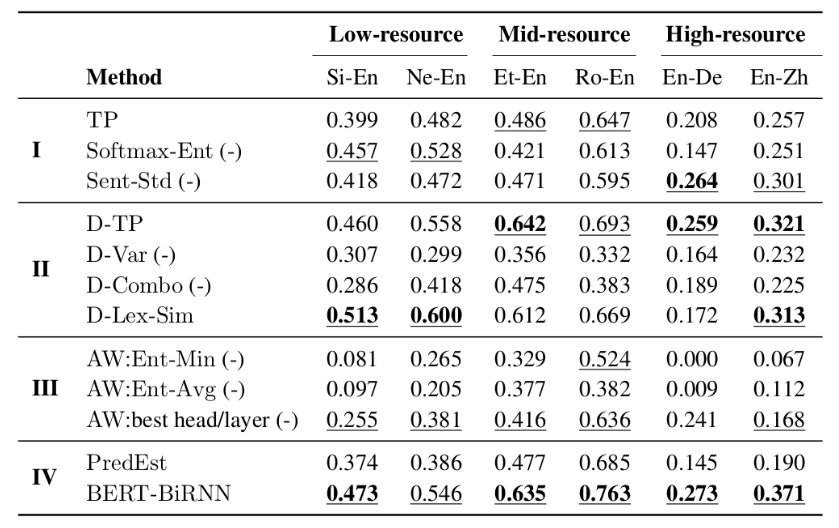
In a recent paper, we attempted to answer this question by framing QE as the closely related problem of estimating the confidence of the MT system in the translation produced, which has the added benefit that it can be done in an unsupervised way, without data labelled for quality. For that, we hypothesised that in a well-trained NMT, a high (low) translation probability could be indicative of high (low) translation quality. To test this hypothesis, we looked at various indicators produced by the NMT decoder that could be used as proxies for sentence-level confidence and, thus, quality:
- The average log-probabilities of the translated words from the softmax output layer of the decoder (TP).
- The average entropy of this softmax output distribution over target vocabulary (Softmax-Ent).
- The standard deviation of word-level log-probabilities (Sent-Std).
- Inference-time dropout, where we randomly mask neurons to zero at decoding time before every weight layer, followed by several forward passes through the network and collect posterior probabilities generated by the model with parameters perturbed by dropout. We then use the mean (D-TP) and variance (D-Var) of the resulting distributions, as well as the ratio of the two (D-Combo).
- Inference-time dropout, where we actually generate multiple translations for the same input with model parameters perturbed by dropout and measure linguistic variability among these different translations (D-Lex-Sim).
- Attention weights, where we collect and combine (via entropy) attention weights in multiple attention heads and multiple encoder and decoder layers of the NMT transformer models, taking the minimum entropy (AW:Ent-Min) and average entropy (AW:Ent-Avg). We also take the best head/layer combination (AW:best head/layer) for an oracle comparison.
Take home message
From these experiments, the main message is that NMT model information can be a useful predictor of quality, especially using uncertainty-based indicators. This unsupervised approach is attractive since it requires no data labelled for quality and can therefore be applied to any language pair. The only requirement is access to the NMT decoder for confidence indicators, and the possibility to decode with dropout for the uncertainty indicators (which in turn requires a model trained with dropout). The computation of these indicators requires no direct changes to the NMT architectures themselves, and in principle can be done with any NMT architecture. However, if the goal is to achieve the highest possible correlation with human scores, benchmarking against supervised QE models is recommended.Where to start if I want to use QE?
QE is a very active area with benchmarks run yearly as part of the WMT open competitions since 2012, offering data and comparing a number of systems. The most recent WMT competition is still open with sentence-level direct assessment prediction, word and sentence-level post-editing effort prediction, and document-level MQM prediction.
Open source tools: QuEst++, deepQuest, OpenKiwi, TransQuest for supervised QE, and the fairseq toolkit for the unsupervised indicators we introduced.