
Introduction
Maintaining consistency of terminology translation in Neural Machine Translation (NMT) is a more challenging task than in Statistical MT (SMT). In this post, we review a method proposed by Dinu et al. (2019) to train NMT to use custom terminology.
Translation with Terminology Constraints
Applying terminology constraints to translation may appear to be an easy task. It is a common practice in the (human) translation industry, often with the help of translation memory (TM) tools. The idea is that for many domains there is already a set of commonly used terms of translation for a language pair. We don’t want to change these comparatively fixed translations while translating them in that domain.
In SMT, there is the phrase table that can be edited after the training of MT models, therefore it is easier to maintain these constraints. However, in NMT, the models are trained directly from the parallel corpus where the words are further “segmented” into subword units (e.g. using BPE) in the aligned sentences. There is no phrase table to edit as the information is incorporated into the trained neural models. Therefore, most approaches apply terminology constraints to the resulting translation in the decoding phase, e.g. Hokamp and Liu (2017).
There are several approaches we could use to provide additional information in the source. For example, for each word of interest that we want to apply terminology constraints, we can append the target term to that word, or simply replace it with the target term. In the proposed methods by Dinu et al. (2019), there is an additional sequence (referred to as “stream”) to be used as input, to indicate which words are from the source sentence, if it is a term either in the source or the target. Fig. 1 shows the annotations of input sentences using the two strategies, Append and Replace.

Figure 1. Comparison of the Append and Replace strategies to provide additional terminology information in the input sentences for NMT training. Source terms are annotated as 1, target terms as 2, and 0 indicates words (other than terms) from the source sentence. Excerpted from Dinu et al. (2019).
Experiments and Results
The NMT models are trained using WMT 2018 English-German news translation tasks. The baseline trained the model “as is.” Terminology databases came from two publicly available sources, Wiktionary (Wikt) and IATE. Table 1 shows the experimental results. We can see that the baseline (NMT without incorporating terminology constraints) could already maintain 77% of the terms that comply with terminology. Using constrained decoding, it is higher than the proposed strategies with Wikitionary and lower with IATE. One notable advantage of the two methods is that it took far less time in the decoding, almost the same as in the baseline, because the mechanism is applied in the training phase.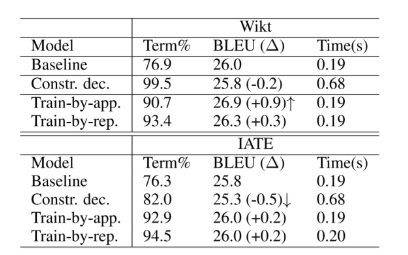
Figure 2. Comparison of performance of using different strategies of terminology constraints. Excerpted from Dinu et al. (2019).