
Introduction
Neural machine translation (NMT) models benefit from large amounts of data. However in high resource conditions, training these models is computationally expensive. In this post we take a look at a paper from Liu et al. (2020) aiming at improving the efficiency of training by introducing a curriculum learning method based on the word embedding norm. The results show that the accuracy of the resulting model is also improved (in terms of BLEU score).
Curriculum Learning (CL)
The standard training process consists of randomly sampling sentence pairs to form mini-batches, until all training data has been sampled. This process is called an epoch and is repeated until the training algorithm converges. Each mini-batch is used to update the loss function.
The idea of curriculum learning is to process the examples in different learning stages, from easier to more difficult. To do this we need a criterion to determine that a sentence pair is easy or more difficult to learn from. Typical criteria proposed in the literature for sentence difficulty are linguistically motivated, such as sentence length or word frequency, or model-based, such as uncertainties derived from independent language models or from the models trained in previous time steps.
The baseline CL approach for the discussed paper is a work from Platanios et al. (2019) based on the notion of model competence. The model competence is a function in the [0,1] range which determines which examples can be sampled at every training step. The example difficulty is projected onto the [0,1] range, and the mini-batch sentence pairs are sampled from the examples with a difficulty lower than the current competence.
Norm-based Curriculum Learning
Liu et al. propose to define sentence difficulty as the sum of the norm of each word embedding vector. This choice is motivated by evidence that:
- the word vector norm decreases with the word frequency, so that less frequent words, which are more difficult to learn, have a higher norm.
- polysemous words tend to have an average norm weighted over its various contexts. Thus, the vectors representing context-insensitive words have a higher norm. These words, usually found in specific contexts, should be regarded as significant words. The more significant words in a sentence, the less common it will be, and the more difficult to learn.
- longer sentences are more difficult to learn, thus word vector norms are added.
In summary, with this metric, long sentences and sentences consisting of rare words or significant words will tend to have a high sentence difficulty for CL. This criterion combines linguistically motivated features (word frequency and sentence length) as well as model-based features (word significance, which depends on the embedding model and can be easily computed).
Liu et al. also introduce the embedding vector norm in the calculation of the competence function. While the embeddings used to calculate the sentence difficulty are pre-calculated at the beginning of training, the embeddings used to calculate the model competence are the ones estimated by the model at each training step.
Finally, a problem with competence-based CL is that the easiest sentences are sampled more often than their actual frequency in the corpus, thus the translation results are biased in favor of the easiest sentences. To mitigate this issue, the authors introduce sentence weights in the loss function, based on the sentence difficulty function, so that more difficult sentences account for a higher part in the loss function variation than the easier ones. In this way the model, at each training step, tends to learn more from those sentence pairs whose difficulty is close to the current model competence.
Results
The norm-based CL approach is tested on two training tasks: a medium-resource task, WMT’14 English–German translation (4.5 million training examples), and a high-resource task, WMT’17 Chinese–English translation (20 million training examples). The main results are summarized in the following table. The training processes are a standard Transformer model training, a baseline competence-based CL training, and the proposed approach. “Best # updates” refers to the number of updates after which the best model was obtained.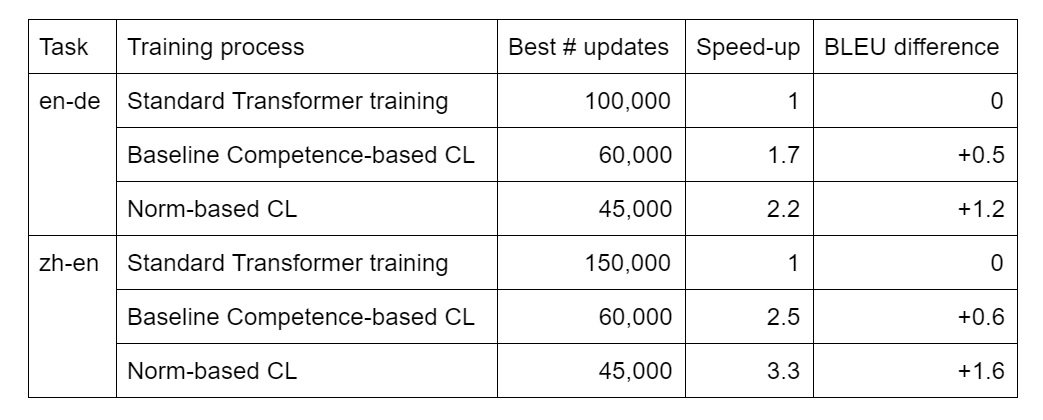 According to these results, competence-based CL allows us to train the models better and faster. And norm-based CL further improves the speed-up and the model quality in terms of BLEU score (up to 3.3x speed-up for the largest task, and 1.2-1.6 BLEU point improvement over the standard training process).
According to these results, competence-based CL allows us to train the models better and faster. And norm-based CL further improves the speed-up and the model quality in terms of BLEU score (up to 3.3x speed-up for the largest task, and 1.2-1.6 BLEU point improvement over the standard training process).
In summary
Neural MT training is computationally expensive, especially for large corpora. Fortunately, curriculum learning allows the training to be better and faster, by learning from easiest to more difficult examples. The sentence word embedding norms are a good way of measuring the learning difficulty of an example. Norm-based curriculum learning achieves better models (1.2-1.6 BLEU score improvement) in up to 3.3 less time. This approach only requires changing the way examples are sampled to form mini-batches during training, and to slightly update the training loss function, a small effort for a win-win strategy.
Author
Dr. Patrik Lambert
Senior Machine Translation Scientist