
Introduction
Unsupervised Machine Translation (MT) is the technology that we use to train MT engines when parallel data is not used, at least not directly. We have discussed some interesting approaches in several previous posts for unsupervised MT (Issues #11 and #28) and some related topics (Issues #6, #25 and #66). Training MT engines requires the existence of parallel data, and these ideas are focused on how to do that with little or no parallel data. In this post, we review a two-step approach proposed by Pourdamghani et al. (2019), called translating “translationese”.
Translating with Translationese
The idea of the two-step approach is simple, whereby a dictionary is used to turn an input sentence into a “translationese”, a pseudo translation, and then an MT engine is trained with parallel data where the source side is also converted to translationese. For the dictionary, rather than using existing ones, Pourdamghani et al. (2019) decided to use automatically built dictionaries, following the approach proposed by Lample et al. (2018). A word-by-word translation is then performed using the automatically built dictionaries to turn input sentences into translationese.
The MT engine itself is a transformer model trained with parallel data which came from a diverse set of high-resource language pairs, where the source sides of these language pairs are replaced by translationese (from word-by-word translation via automatically built dictionaries). Therefore, there is only one model to translate all the translationese “sentences” into the target language. 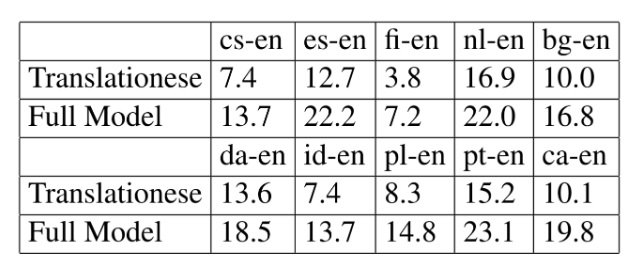 Table 1. Translation results (in terms of BLEU scores) on Czech (cs), Spanish (es), Finnish (fi), Dutch (nl), Bulgarian (bg), Danish (da), Indonesian (id), Polish (pl), Portuguese (pt), and Catalan (ca). Excerpted from Pourdamghani et al. (2019).
Table 1. Translation results (in terms of BLEU scores) on Czech (cs), Spanish (es), Finnish (fi), Dutch (nl), Bulgarian (bg), Danish (da), Indonesian (id), Polish (pl), Portuguese (pt), and Catalan (ca). Excerpted from Pourdamghani et al. (2019).
Experiments and Results
The table shows the BLEU scores of the translationese and the resulting translation on ten language pairs. Pourdamghani et al. (2019) also show that the MT engine in general performed better on high-resource language pairs, e.g. French-to-English, and Russian-to-English. The benefits the approach brought about are:1) using pseudo-translation (translationese) to minimize the complexity MT engines need to learn from the source language, and
2) training a single model to translate from translationese (which are automatically turned from various source languages) to the target.
Therefore, the MT engine itself can focus on learning to translate from translationese (a “kind” of target language) to the target language.