
Introduction
Semantic representations were part of the very early Machine Translation (MT) systems, yet have had little role in recent Neural MT (NMT) systems. Given that a good translation should reflect the meaning of the source text, this seems an important area to focus on, particularly since the abstraction could potentially help handle data sparsity. In today’s blog post, we look at work by Song et al (2019) which is a first attempt to incorporate Abstract Meaning Representation (AMR) as a semantic representation for NMT, and significantly improves on the baseline.
The only previous attempt to incorporate semantics in NMT has involved Semantic Role Labelling (Marcheggiani et al. (2018)), which incorporates a shallow representation in the form of arguments and predicates. This in itself helps resolve issues with translating passive/active voice. AMR goes further: it encapsulates the meaning of a sentence as a directed graph, where the nodes are concepts (such as give-01 and John below) and the edges are the relations between the concepts. As can be seen from the diagram below extracted from Song et al (2019), this allows it to represent much more information: 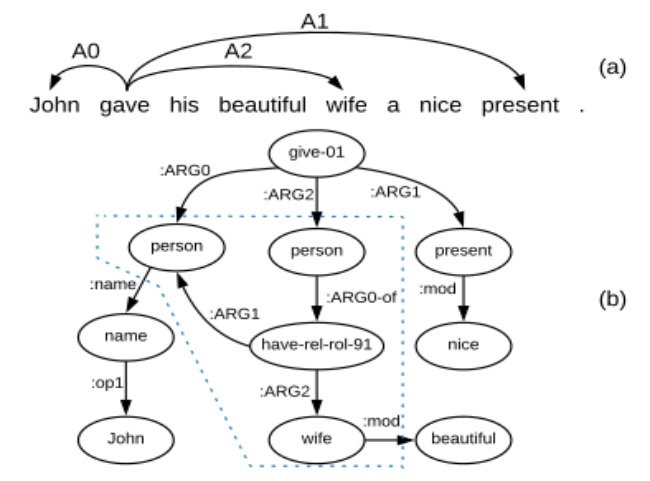 Figure 1: (a) A sentence with semantic roles annotations, (b) the corresponding AMR graph of that sentence.
Figure 1: (a) A sentence with semantic roles annotations, (b) the corresponding AMR graph of that sentence.
The fact that AMRs encapsulate the entity relations and abstract away inflections means that they can help reduce data sparsity, and are complementary to lexical input. Unsurprisingly, therefore, the improvement increases in scenarios with less data.
Incorporating AMR
In order to incorporate AMRs into NMT, Song et al (2019) use a Graph Recurrent Network (GRN), building on their previous work (Song et al (2018)) for an AMR to sequence generation model, and apply it to machine translation. Their architecture incorporates:- a bidirectional LSTM on source side for encoding the source sentence (bottom left of diagram below),
- a GRN (bottom right) which encodes the AMR (this incorporates multiple recurrent transitions, as indicated by gT),
- an attention based LSTM decoder to generate the output sequence, with attention models over both of the above.
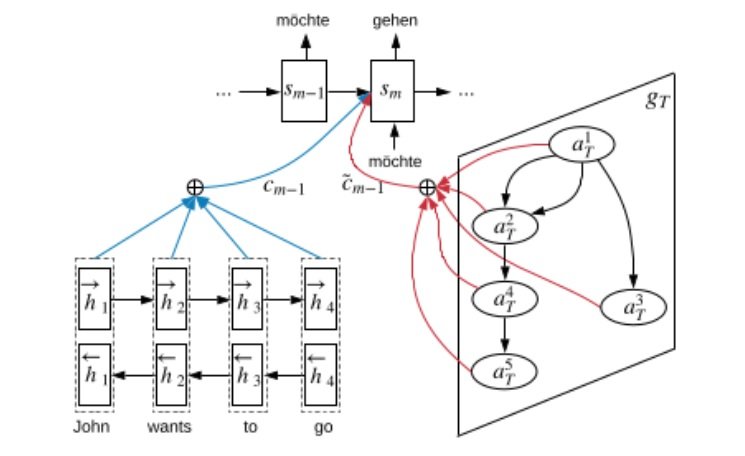 Figure 2: Overall architecture of our model.
Figure 2: Overall architecture of our model.
Encoding AMR with GRN: an AMR graph G = (V, E) represents nodes and edges. Non-local information exchange between nodes is assured via state transitions. The state transition process is modeled with an RNN, where a hidden state vector captures state transitions for each node, encapsulating the interactions between it and all connected nodes for transitions T (experiments are done with varying number of transition steps T). Each state transition incorporates information on the interconnected nodes and relations, and is gated to control information flow (for more detail on inputs see 4.1 of Song et al (2019)). With each state transition information is passed from each node to its adjacent nodes recursively. The information from the AMR graph is integrated into the baseline model whereby the last graph state becomes the attention memory passed to the decoder and incorporated into the output probability distribution over the target vocabulary. The data used in this experiment was WMT16 English-German dataset, and the News Commentary subset of it. The English sentences are parsed into AMRs before BPE is applied.
Results
Compared against Transformer-tf, OpenNMT and an attention-based LSTM baseline, this Dual2Seq model which incorporates a sequential and a graph encoder with a doubly attentive decoder consistently outperforms under all 3 metrics, and significantly over the first two baselines, a clear indication of the value that incorporating AMRs brings. The improvement is larger under the limited data setting, indicating that the AMR is useful in that scenario. The gains are greater when evaluated with Meteor, and the authors surmise that this is because unlike BLEU it gives partial credit to synonyms, and that AMR structural information aids the translation of concepts. They experiment with various semantic representations, including SRL and a linearised AMR representation, and show that their graph-based approach outperforms them all.
Human evaluation is conducted with German-speaking annotators to determine which translations (from reference, baseline and Dual2Seq) better captures the predicate-argument structures of the source. From the 100 instances from testset, Dual2Seq won on 46, with a tie on 31, a clear indicator that the AMRs improve translation of predicate-argument structures.
In summary
Given how vital meaning is for a translation, it is exciting to see work to incorporate semantic representations into NMT. For the first time, AMRs are incorporated directly via a graph-based approach which proves the most productive method in the experiments conducted. The results show a clear improvement across the board, which increases when evaluation moves beyond string comparisons. The resulting abstraction of structural information means is particularly useful for low-resource scenarios.
Author
Dr. Karin Sim
Machine Translation Scientist